
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR











こんにちは。
セキュリティーソリューション統括部の阿久津です。
SaaSサービスでよく課題となる「短期間でログが消えてしまう問題」を解決すべく、自動的にログを保管する仕組みを構築しました。しかし、仕組みが想定外の動作をしてしまい、長期休暇中に300万近く課金されてしまうという恐ろしい事態に......。
自動化を考えている皆様のご参考になればと、この顛末をお話ししたいと思います。
※ AWS環境の例で記載しますが、自動化に関わる全製品に共通する内容と考えています。
構築した仕組みの構成
外部サービスのOktaのログをアクセス傾向分析に使用するため、長期間のログを保存すべくAWS環境を用いて仕組みを構築しました。Oktaについては、過去にLAC WATCHに掲載した記事も併せて参照ください。
具体的には、以下の流れでログを保存するように実装をしました。
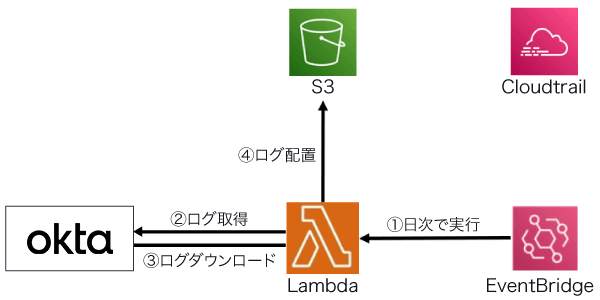
- (A)Lambda上でOktaのログをJSON形式で日次ダウンロードし、S3に配置
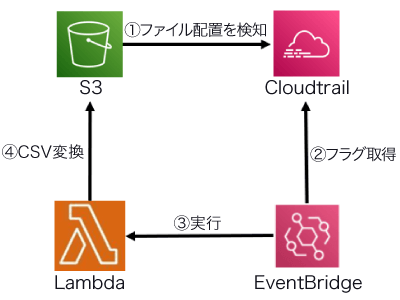
- (B)S3上にファイルが配置されたのをCloudTrailで検知し、S3上のJSONファイルをCSVファイルに変換
仕組みの構成としては、以下の通りです。
(A)の構成
(B)の構成
発生した事象
上記(A)(B)について以下のように動作し、無限ループが発生しました......。
想定動作
- (A)日次でOktaのログをJSON形式でダウンロードし、S3に配置
- (B)配置されたJSONファイルをCSVファイルに変換(1JSONファイルに対し、1CSVファイルを作成)
実際の動作
- (A)日次でOktaのログをJSON形式でダウンロードし、S3に配置
- (B)配置されたJSONファイルをCSVファイルに変換する際に複数のCSVファイルを作成する無限ループが発生
1日1回のみ動く想定だったのが、実際は1分あたり160万回以上も実行されていました。
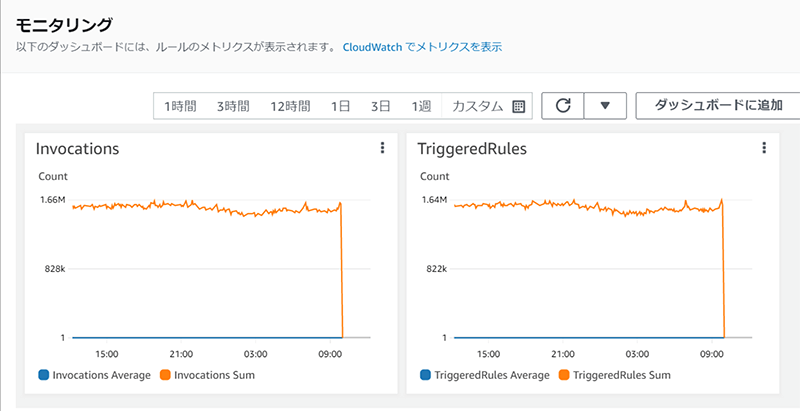
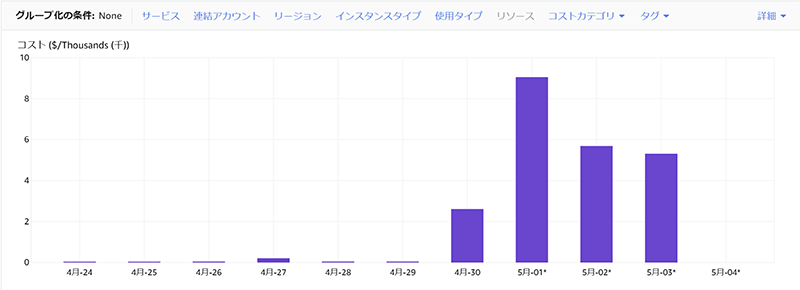
しかも、無限ループが発生したことで5日間総額約300万円になっていました!
サービスごとの費用内訳
| Lambda | Lambda | コール数によって課金、約10万 |
|---|---|---|
| Cloudtrail | コール数によって課金、約70万 | |
| EventBridge | コール数によって課金、約80万 | |
| S3 | ストレージ内の容量、リクエスト数に応じて課金、約90万 |
各サービスに加え、サポート費用、消費税諸々含め300万以上の課金が発生しました。
幸い今回の事象はラックの検証環境上で発生した事象のため、お客様への影響はなかったものの、これが「もしお客様環境で起きていたら......」と考えると背筋が凍ります。
事象の原因
今回上記(A)(B)の仕組みを定期的に実行する想定で各々EventBridgeルールの設定をしましたが、(B)のEventBridgeルールの設定に考慮漏れがありました。
具体的には、以下のように記載をしていました。
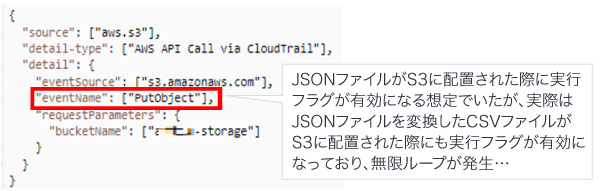
EventBridgeルールの作成時、イベントパターンのフォームから生成したJSONとなります。
※ S3にオブジェクトが配置されたら後続処理を実施するというテンプレートを使用しました。
テンプレートの内容を深く理解せず、そのまま流用したことが本事象の発端となっていました。
※ ただ、EventBridgeでは、ルールが繰り返し開始される無限ループにつながるルールを作成する可能性があります。EventBridgeのルールを記述する際は、細心の注意を払いましょう。
AWS CloudTrail を使用して AWS API コールでトリガーする CloudWatch Events ルールの作成 - Amazon CloudWatch Events(https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/events/Create-CloudWatch-Events-CloudTrail-Rule.html)
また、上記の仕組みを実装したのが長期休暇直前ということもあり、リアルタイムで無限ループに気づけなかったということも費用が嵩む原因となりました。(そもそも長期休暇前にEventBridgeを止めるべきでした......)
今後の教訓
今後の教訓として「プログラムの誤動作を早急に気付くためにどのようにすればいいか」という観点で記載します。
(プログラムや製品への理解を深めるのはもちろんなのですが、それだけではあまり汎用的な教訓にならないため、視点を変えています)
監視を行う
機能実装後にすぐ長期休暇に入ったこともあり、検証環境の運用管理者チームも含めて誰もAWS環境を監視している状態でなかったことで異常の発生が遅れてしまいました。
本番環境については当然監視を実施すると思いますが、自動化を実装するにあたり、リリース前の時点でも監視を実施して問題なく機能しているか確認する必要があると思います。1日1回確認するといったように本番環境と同じ頻度で実施する必要はなくとも定期的に確認する体制を整えておけば、異常が発生してもすぐに気づけるように思いました。
一定コストに達した際のアラームを設定する
機能としては問題なかったとしても、セキュリティインシデント等で思わぬ費用計上が発生することは往々にしてあると思います。そこでコストアラームを設定することで一定額に達した際に気付くことができ、想定外の出費を防ぐことができると考えています。
終わりに
昨今のIT情勢として、インフラエンジニアとアプリエンジニアの垣根がなくなり、フルスタック型のエンジニアが求められている気運となっています。入社以来インフラエンジニアだった私でも、アプリケーションの知見が必要だと実感しています。
当たり前の話ですが、システムを構築するにあたり「システムとして一旦動く」ところまでを目指すのではなく、その先の「今後も問題なく動くかどうか」「異常が起きた際の体制の構築」まで考えてシステムを構築しなければいけないと改めて痛感しました。
ちなみに、今回発生した金額について会社からはもちろん怒られました。当たり前ですよね......、すみません。この教訓をもとに、人為的なミスを早期対応できる仕組み作りにも励んでいきたいと思います。
この記事をシェアする
関連記事








タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR