
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- AIエージェント
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR











こんにちは。AIプロダクト開発グループの青野です。
一昨年のChatGPTの台頭により、生成AIが注目を集めていますね。今はそれを社内でどう活用していくかというのが各社持ちきりだと思います。ラックでも生成AIを革新的な技術の一つとして、日々技術検証をしています。
今回は、生成AIのアーキテクチャの一つであるRAGの評価についてご紹介したいと思います。
ラックの生成AIの取り組み
ラックでは、Azureでセキュアかつ容易に再現可能なインフラを構築し、ChatGPTと同じようなチャットUIを開発しました。これは社内で使えるChatGPTとして機能しており、業務効率化に繋がっています。
そのチャットアプリは「LACGAI powered by OpenAI(以下、LACGAI)」といい、社内ではコストを意識せずGPT-4を使うことができ、社内で共有できるプロンプト事例集も搭載しています。
また、各部署では生成AIを使った業務効率化に向けて試行錯誤がなされています。その一環として、LACGAIの構築当初に社内規程集について答えてくれる生成AI(以下の図ではCompanyと表記)をGPT-3.5やGPT-4と同列で搭載しました。
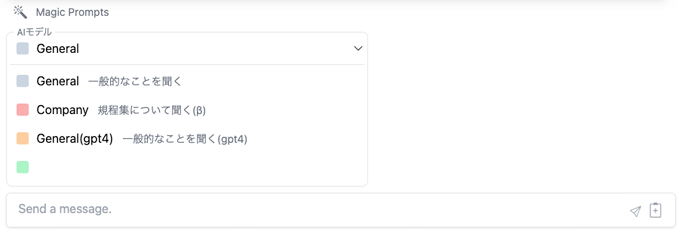
この社内規程集について答えてくれる生成AIは、「工夫することで生成AIが社内の情報を扱える」というイメージを社員に持ってもらう、デモ的な意味合いを持って搭載しました。
さて、このAIのアーキテクチャをRAG(説明は後述)といいます。今後困ってしまうのは、いざ各部署から「業務効率化のために、部署内のデータを使って、部署内の知識を答えてくれるようなAIを作りたい!」と言われた時に、RAGを評価するノウハウがないということでした。
私自身も、最近RAGの進化版がどんどん世に出てきていて試したいとは思うものの、まずはきちんとした評価ができなければ、そのRAGの進化版は普通のRAGより果たして本当に精度がいいのか?という問いに答えることができません。
そこで、ノウハウを身につけるため、社内規程集RAGを使って評価の流れを一通りやってみましたので、これからその流れを説明していきます。
以降の内容は、まだまだ発展途上な領域というのもあり、あくまで私が色々と調査しながら「やってみた」という範囲の内容です。必ずしもベストプラクティスを申し上げるわけではないことを留意いただきつつ、少しでも参考になれば幸いです。
また、生成AIとは?ChatGPTとは?といったところから話すと、ただでさえ長い記事がさらに長くなってしまうので、ChatGPTをある程度使ったことがあることを前提とさせていただければと思います。
RAGとは
RAGとはRetrieval Augmented Generationの略で、通常の生成AIに検索エンジンを組み合わせることで生成AIが保持していない知識の事柄を答えてもらおうというものです。
イメージは、図書館から本を探してきて、自分の知識にない情報を補うといった感じでしょうか。このとき、その本の内容を学習せず参照するだけに留めるというところが肝です。
RAGを使うことで、よくあるAIのイメージの「専門知識をAIに答えてもらうようにするためには性能のいいパソコンで難しい学習をさせないといけない」といったことがなくなります。あくまで、生成AIに追加で学習させるのではなく、情報を参照してもらうだけです。
RAGのChatGPTでのイメージは下記をご参照ください。質問と検索エンジンから取得してきた文章をそのままChatGPTにプロンプトとして入力します。指示は「参照文書をもとに質問に回答してください。」と入力しています。

この指示とそれ以降の情報でChatGPT自身が持っている知識からではなく、参照文書から答えてくれます。このように、RAGを用いることで、蓄積した社内情報や部内のノウハウを自然言語で回答してもらえるため、問い合わせへの対応やノウハウの横展開、専門家育成のツールとして活用できるのではないかと見られています。
しかし、一方でRAGのG(Generation)、つまり"生成"は本当に必要なのか?という議論もあります。場合によっては、文書をきちんと整備してそれらの文書を検索できるようにするだけで、十分にニーズが満たされる可能性もあります。RAGを使うということは、少なからずAI、つまり不確実なものが入り込みます。そのため、検索してヒットした文書を人が読む方が確実かつ適切であるユースケースもあるでしょう。
それでも、例えば以下のようなユースケースはRAGのGも必要になってきて、RAGの工夫のしがいがあるところといえます。
- 生成した文章を何らかのレポートやメールの返答に使うことで業務効率が大幅にアップする見込みがある。
- 蓄積した文書に情報がない場合は、生成AIの内部知識で答えて欲しい。
- 英文の文書が蓄積されているけど、質問に対して日本語に翻訳された回答が欲しい。
本来はRAGが本当に必要かどうかを議論する必要がありますが、今回は「やってみた」のため上記の議論は飛ばしています。また以降、自然言語を扱うAIを使ったRAGの話なので、生成AIモデルを示す単語はLLM(Large Language Model)と記載します。
RAGのPoCの流れ
一般的な流れは以下の通りです。以降は、RAGを改良・評価していく人(データサイエンティストと呼ぶことにしますが、通常はその限りではありません)の目線で書いていきますが、これからの流れは、データサイエンティストに依頼する側であり、RAGを実際に使っていく業務の方々の協力も必要ですので、そういった方々にもぜひ読んでいただければと思います。
- 1.評価指標を決める
- 2.精度目標を決める
- 3.評価用データセットを作成する
- 4.評価したいRAGに質問を入力し回答を生成してもらう
- 5.評価用データセットの回答と生成された回答を照らし合わせて評価する
本来、4と5は2で決めた精度目標を達成するまで、RAGを改良しながら繰り返すことになります。
1. 評価指標を決める
まずは評価指標を決める必要があります。どういった評価指標でRAGを評価したいかによって、準備する評価用データセットも変わってきます。
評価指標をどう決めようか......。まずは世にあるライブラリを調査してみました。
MLflowは以前からあるAIの実験管理ライブラリで、RAG評価のモジュール開発に絶賛取り組んでいます。MLflowで用意されている評価指標をいくつか見てみます。
Answer Correctness
LLMが生成した回答がground truthと比較してどれだけ正しいかを測る指標です。
データセットとしては、質問とground truthを用意する必要があります。ground truthとは、ここでは質問に対する真の回答という意味になります。一般に人が作成する必要があります。
Answer Relevance
LLMが生成した回答が質問とどれだけ関連があるかを測る指標です。
データセットとしては、質問のみを用意する必要があります。
Faithfulness
検索エンジンから取得した文書に基づいて、LLMが生成した回答がどれだけ忠実であるかを測る指標です。
データセットとしては、質問のみを用意する必要があります。
このように、ground truthが必要でない指標もあります。ただしground truthが必要でない指標は、例えば検索エンジンに登録するデータが膨大で、ground truthが容易には作れない、つまり1問に対して何答もあるような場合に使うのだと思われます。社内規程集のように比較的1問1、2答くらいであれば、Answer Correctnessのような指標で評価し、「RAGがどれだけ正しい回答をしてくれるか」を知ることができる方がいいのではないでしょうか。
ということで今回はMLflowを参考にし、「Answer Correctness」と、独自で「Retrieval Correctness」という指標を作り、1〜5の5段階で評価していこうと思います。
Retrieval Correctness(独自作成)
検索エンジンから取得された文書を使って、どれだけ正確にground truthを生成できるかを測る指標です。
データセットとしては、質問とground truthを用意する必要があります。
これは、検索エンジンから取得された文書からground truthを生成できなければ、検索エンジンが必要な文書を取得できていないことになります。反対に生成できれば、必要な文書を取得できているということを意味します。RAGは検索エンジン+生成AIのアーキテクチャです。そのため、Retrieval Correctnessは検索エンジンの性能を測るような指標として定義してみました。
Answer CorrectnessとRetrieval Correctnessは独立で評価していきますが、解釈としては組み合わせで以下のような4パターンになります。
| パターン1 | Retrieval Correctnessも高く、 Answer Correctnessも高い場合 |
検索エンジンから適切な文書が取得でき、その情報からLLMも正しい回答を生成できている。 |
|---|---|---|
| パターン2 | Retrieval Correctnessは高いが、 Answer Correctnessは低い場合 |
検索エンジンから適切な文書が取得できているが、その情報からLLMは正しい回答を生成できていない。 ※ これはLLMのハルシネーション(AIがもっともらしい嘘を生成する現象)が起きているといえます。 |
| パターン3 | Retrieval Correctnessは低いが、 Answer Correctnessは高い場合 |
検索エンジンから適切な文書が取得できていないのにも関わらず、LLMが正しい回答を生成できている。 ※ これはあまり起きえないでしょう。 |
| パターン4 | Retrieval Correctnessも低く、 Answer Correctnessも低い場合 |
検索エンジンから適切な文書が取得できておらず、その結果LLMも正しい回答を生成できない。 |
| パターン1 |
|---|
| Retrieval Correctnessも高く、Answer Correctnessも高い場合 |
| 検索エンジンから適切な文書が取得でき、その情報からLLMも正しい回答を生成できている。 |
| パターン2 |
| Retrieval Correctnessは高いが、Answer Correctnessは低い場合 |
| 検索エンジンから適切な文書が取得できているが、その情報からLLMは正しい回答を生成できていない。 ※ これはLLMのハルシネーション(AIがもっともらしい嘘を生成する現象)が起きているといえます。 |
| パターン3 |
| Retrieval Correctnessは低いが、Answer Correctnessは高い場合 |
| 検索エンジンから適切な文書が取得できていないのにも関わらず、LLMが正しい回答を生成できている。 ※ これはあまり起きえないでしょう。 |
| パターン4 |
| Retrieval Correctnessも低く、Answer Correctnessも低い場合 |
| 検索エンジンから適切な文書が取得できておらず、その結果LLMも正しい回答を生成できない。 |

2. 精度目標を決める
評価指標を決めた後、本来なら業務・事業に活用していくRAGを作るので、「Answer Correctnessは最大値5のうち平均4以上ないと業務性質上使えません」といった風に目標を決めます。そうして、その目標を達成するまでデータサイエンティストがRAGの改良と評価を繰り返していきます。
今回は、「やってみた」であり、社内規程集RAGの評価目標は設定しません。本来は必須です。
3. 評価用データセットを作成する
次に評価用データセットの作成です。RAGを改良するたびに上で設定した評価指標を使って評価することになるのですが、評価用データセットを作成し同じ質問で評価しなければ、RAGの改良版v1と改良版v2を比較できません。
今回は、各規程を所管する部署に協力してもらい、社員がしそうな質問と、その質問に対するground truth(真の回答)も規程から抽出に近い形で用意してもらいました。一部、曖昧な質問やground truthを修正し、全80問の評価用データセットを作成しました。
4. 評価したいRAGに質問を入力し回答を生成してもらう
評価用データセットができたら、RAGに評価用データセットにある、決められた質問を入力して、回答を生成してもらいます。
5. 評価用データセットの回答と生成された回答を照らし合わせて評価する
最後に評価の部分です。1で決めた評価指標の定義に従い、RAGに生成してもらった回答と部署の方に作ってもらったground truthと照らし合わせます。
方法としてパッと思いつくのは人手での評価です。決めた評価指標の定義とスコアリングの方法などを評価してもらう方に教示し、実際に評価をしてもらいます。人手評価は以下に気をつける必要があります。
今後そのRAGを使っていく業務の方々に評価してもらう
業務で使うようなRAGの場合は、専門知識を扱うことが多いはずです。そのため実際に今後そのRAGを使う方々に評価してもらう方が好ましいです。それは、評価の精度にも関係しますが、「評価への納得感」を業務の方々に得てもらうために必要なことです。PoCはデータサイエンティスト1人では完結しません。現場の方々の協力が非常に大事になります。
人手評価は絶対的に正しいわけではないので、複数人で評価する
複数人で評価すること自体は特筆する必要はないでしょう。しかし、例えば1〜80問の評価で、1問〜80問を順番に答えてもらうのではなく、ランダムに提示することも大事です。
1問1問独立しているのだからいいだろうと思いがちですが、人の頭はそうはいきません。頭の中で前の問題の評価が次の問題の評価に影響してしまうことがしばしば起きます。このバイアスはどうしても起きてしまうため、そのバイアスを均すという意味で、各人に対してランダムに提示するという方法を取ります。
複数人での評価方法がぶれないように評価ガイドラインを用意する
これが地味に大変です。「誰が読んでも同じように解釈される文章」を書くのは簡単なようで非常に難しいです。
RAGの評価の方法の記載はもちろんのこと、RAG自体の説明を丁寧に記載することや、評価作業にあたり静かな環境を用意して実施してもらうこと、評価指標の定義を毎回確認してもらうこと、適宜休憩を挟んでもらうことなどをガイドラインに含める必要があります。
評価者にストレスを与えないような準備をして依頼する
前述と少し関連しますが、評価者の心理状態が評価に影響を与えかねません。また、評価作業のやりやすさでヒューマンエラーの程度が変わってきます。
例えば以下の例では、次は#7を評価しないといけないわけですが、ぱっと見どちらが次の番号を把握しやすいでしょうか。「こんなのどっちでもすぐわかるよ」と思う方もいらっしゃるかもしれませんが、同じ作業を繰り返していると、こういった小さな差が影響していきます。表に各質問の評価に必要なリンクを貼ることも有効です。
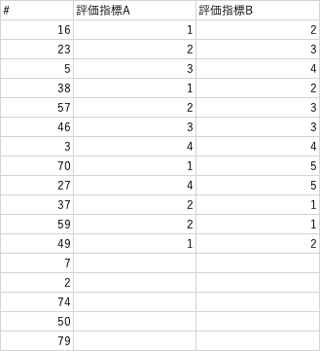
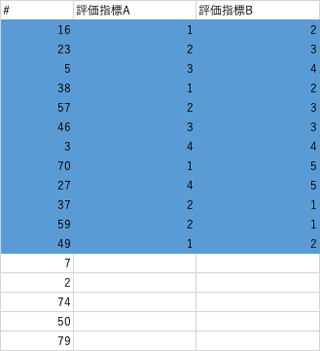
このように評価者にできるだけストレスを与えないような評価用ファイル(時にはアプリケーション)を用意します。一度依頼する側で実際に評価作業をやってみて、やりづらいところやわかりづらいところを直す作業も大事になってきます。
人手評価の話を長々しましたが、もし人手評価だけに頼るなら精度目標に達するまで、データサイエンティストがRAGを改良するたび、複数人に評価依頼をしないといけないことになります。気が遠くなりそうです。
そこで、ここでもLLMの出番です。LLMに評価してもらおうというのが、自然言語の評価方法の一つとして出てきました。そんなに難しい話ではなく、プロンプトを用意してあげるだけです。単純なイメージはこんな感じです。
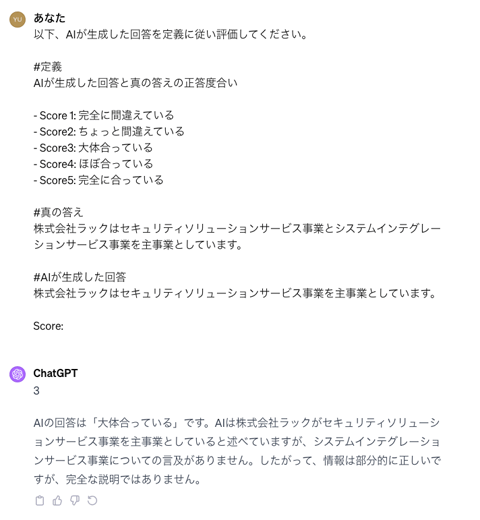
指標を詳細に(イメージでは雑ですが)定義し、評価に必要なデータ、ここでいうと「真の答え」と「AIが生成した回答」を与えて評価するよう指示します。このように指示した結果、ChatGPTが「3」と答えてくれています。
なお、イメージには載せていませんが、「こういった場合は、スコアは3だよ」という例をプロンプトで示してあげるのも有効です。ちなみに、「なぜそのスコアとしたのか」というスコアリングの理由も生成でき、今回はそれも併せて指示します。
こうして、今回設定した評価指標であるRetrieval CorrectnessとAnswer Correctnessの両方の「評価用AI」をプロンプト指示で作ることで、RAGの改良のたびに人手評価をする必要がなくなります。早速これを使ってRAGを自動評価しましょう!
......、ちょっと待ってください。
本当にこの「評価用AI」はちゃんと評価してくれるのでしょうか?でたらめなスコアを出さないでしょうか?
評価用AIの評価
そこで今回は人手評価のスコアと評価用AIによる自動評価のスコアを比較し、どの程度自動評価のスコアが人手評価のスコアとマッチしているかを確認することで、評価用AIの「評価」、妥当性の確認をしていきます。
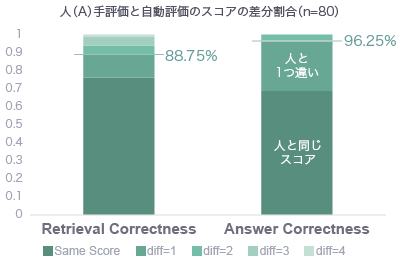
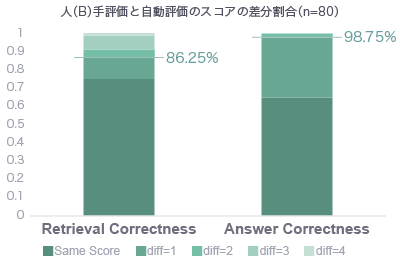
以下の棒グラフが結果です。人手評価は2人にやってもらいました。各人の評価と自動評価の差分の割合を比較しています。
全80問を母数とし、一番下の濃い緑色が、人と評価用AIが同じスコアで評価した質問の割合です。そしてその次に濃い緑色が、例えば人が「5」と評価し、評価用AIが「4」と評価するといったスコアが1つ違いの割合です。
人手評価と自動評価の差
どういう場合に人手評価と自動評価に差が生じているのか、いくつか見ていきます。
- Retrieval Correctness:検索エンジンから取得された文書を使って、どれだけ正確にground truthを生成できるかを測る指標(=検索エンジンの性能を測るための指標)
- Answer Correctness:LLMが生成した回答がground truthと比較してどれだけ正しいかを測る指標
Answer Correctnessで、人手評価「5」、自動評価「4」の場合
このパターンがAnswer Correctnessの人手評価と自動評価の差が生じたパターンで最も多かったのですが、ある質問に対して、RAGによる回答が「12条によると......と定められています」と丁寧に回答してくれている一方で、こちらで用意したground truthは「......と定められています」としていました。
これを人が評価した場合、合っているから「5」となります。しかし、評価用AIは「ground truthには12条とは書かれていませんので、4です。」と述べていました。つまり、評価用AIがかなり厳密に評価をしてくれているのです。そのため、Answer Correctnessで「4」と評価された質問回答ペアはほとんど正答で、むしろRAGがground truthよりも詳細に回答してくれているパターンでした。
Answer Correctnessで、人手評価「1」、自動評価「3」の場合
ある質問に対して、RAGによる回答が「従業員本人からの個人情報の訂正や追加の請求を受けた場合は......」と、従業員の健康情報の取り扱い規程から回答している一方で、ground truthは「本人または代理人からの個人情報の訂正や追加の請求を受けた場合は......」と、個人情報保護方針から作成しています。
人が評価した場合、よく見ると意味合いが異なる文章であると分かりますが、評価用AIはこれを小さな間違いだと判断したようです。文章自体も非常に類似しており、しばしば人手評価でも判断が分かれることがありそうです。
Retrieval Correctnessで、人手評価「1」、自動評価「5」の場合
人がground truthの作成のために参照した規程文書ではなく、類似の規程文書を検索エンジンから取得してきており、評価用AIが「この取得してきた文書を使って、ground truthを作成できます」と判断してしまうパターンです。
例えばground truthは投資管理規程から作り、RAGは投資ガイドラインから回答を生成している場合などです。こういったパターンは「投資とは何か」といった曖昧な質問でground truthを複数文書から作成できてしまうような場合に起きました。
評価用AIによる自動評価の結果
このように人手評価と自動評価に差が生じているパターンは、人手評価でも判断が分かれそうなパターンや評価用データセットの一部質問回答ペアの作り方の問題であることがしばしばあり、ground truthを作る難しさを物語っているといえます。
さて、上記のような差が見られましたが、総評すると、評価用AIが人と同じスコアまたはスコアが1異なる割合は以下のような結果となり、評価用AIは人手評価とある程度類似したスコアリングをしてくれているといえます。
- Retrieval Correctnessで各人88.75%、86.25%
- Answer Correctnessで各人96.25%、98.75%
人手評価はしばしばバイアスや単純ミスも起こりうることを考えると、評価用AIを使って自動評価することはRAG同士を相対評価する上では十分に有用なツールになりそうです。
まだまだ評価用AIはプロンプトエンジニアリングにより改良の余地がありそうですが、今回はRAG評価の流れを掴むことを目的としているため、このRetrieval CorrectnessとAnswer Correctnessの2つの評価指標を測ることができる評価用AIを使って実際に社内規程集RAGを評価してみました。なお、評価用AIのLLMはGPT-4で統一しています。
RAGのパラメータ
今回はRAGで設定できるパラメータをいくつか変えて、どの社内規程集RAGが最も精度が良いかを見てみたいと思います。
パラメータ① 検索エンジンに登録する規程文書の長さ
検索エンジンに登録する際、規程文書をそのまま登録することも可能ですが、検索の精度の問題やLLMにプロンプトとして入力できる文章の長さの制限から、規程文書の文章を分割して登録するという方法を一般的にとります。これは、どれくらいの長さで文書を分割して検索エンジンに登録するかのパラメータです。
今回はおよそ250、500、1,000文字で分割して登録するパターンを試してみました。「およそ」といっているのは、文章の中途半端なところで切らないように分割するため、ぴったりこれらの文字数というわけではないということです。
また、中途半端な文脈で途切れてしまうことを軽減するため、25%程度文章を被らせながら分割します。
パラメータ② 分割した規程文書の入力数
パラメータ①で分割した文章をどれくらいLLMに入力するかというパラメータです。今回はおよそ2,000文字分と4,000文字分と設定してみました。
例えば、パラメータ①で250文字に分割して検索エンジンに登録した場合、2,000文字分というのは8文書分をLLMに入力することになります。当たり前ですが、2,000文字よりも4,000文字の方が、LLMが確認できる情報が多いということになります。
パラメータ③ 検索方法
今回検索エンジンとして、AzureのサービスであるCognitive Searchを利用しています。その検索方法として、以下の3つの方式があります。
- ベクトル検索
- ハイブリッド検索
- セマンティックハイブリッド検索
今回は、下にいけばいくほど高度な検索方法であるとだけ把握いただければ良いかなと思います。
パラメータ④ LLM
これは質問と検索エンジンから取得した情報を、どのLLMに入力して回答してもらうか、というパラメータです。
今回は以下で設定してみました。
- GPT-3.5-Turbo
- GPT-4
- GPT-4-Turbo
GPT-4-Turboはあまり見慣れないかもしれませんが、OpenAIの2023年のDevDayで発表された新しいGPT-4モデルです。今までの約16倍のトークンを扱えるようになっています。
RAG評価結果
いよいよ評価用AIを使った各RAGの評価結果です。
評価結果Ⅰ
まずは、パラメータ①とパラメータ②を変えたRAGを評価してみます。
なお、パラメータ③はハイブリッド検索、パラメータ④はGPT-4で固定しています。
- Retrieval Correctness:検索エンジンから取得された文書を使って、どれだけ正確にground truthを生成できるかを測る指標(=検索エンジンの性能を測るための指標)
- Answer Correctness:LLMが生成した回答がground truthと比較してどれだけ正しいかを測る指標
それぞれの評価指標の数値結果は評価用データセットの80問に対して評価したスコアの平均値です。5に近ければ近いほど良いということになります。加えて、Answer Correctnessでスコアが4と5の割合を「正答率」とし、以降の表を提示します。
| ②分割した規定文書の入力数 | 約2,000文字分 | 約4,000文字分 | ||||
|---|---|---|---|---|---|---|
| ①検索エンジンに登録する 規定文書の長さ |
250 | 500 | 1,000 | 250 | 500 | 1,000 |
| Retrieval Correctness | 4.41 | 4.22 | 3.75 | 4.76 | 4.43 | 4.14 |
| Answer Correctness | 3.80 | 3.81 | 3.28 | 4.05 | 4.04 | 3.71 |
| Answer Correctnessの 4、5の割合(正答率) |
0.71 | 0.68 | 0.50 | 0.76 | 0.76 | 0.64 |
結果として「250文字で分割した文書を検索エンジンに登録し、質問と関連する4,000文字分(16文書)の情報をLLMに入力して回答してもらう」パターンがいいことが分かりました。
もう少し詳細に見ていきます。横軸にRetrieval Correctness、縦軸にAnswer Correctnessで1〜5のスコアのヒートマップになっています。中の数字は質問数になりますが、例えば左のヒートマップでいうと、24問がRetrieval CorrectnessもAnswer Correctnessもいずれも「5」と評価された、ということになります。解釈方法としては再掲しますが、こちらと対応します。
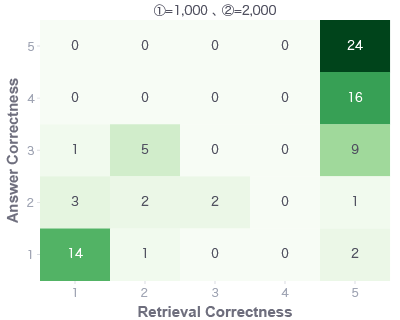
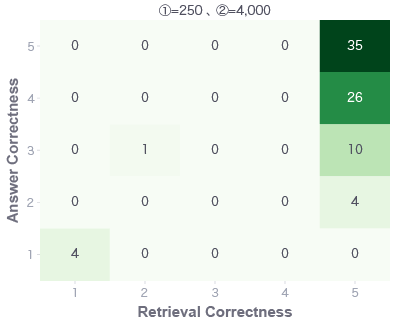
1,000文字で分割した文書を検索エンジンに登録し、質問と関連する2,000文字分(2文書)の情報をLLMに入力した場合(左)はRetrieval Correctness=1が14問もあります。ground truthを生成するための情報が足りないことを示しています。
今回の社内規程集RAGでは250文字程度に分割した文書を検索エンジンに登録した方が良い結果となりました。パラメータ②の方は直感的で、より多い情報をLLMに入れた方が良い結果となっています。
ちなみに以下のような就業規則の太文字までが大体250文字なので、短い感じがしましたが、これは評価用データセットの質問の内容にも依りそうです。長い情報を必要とする質問がより多ければ、1,000文字で分割した方が精度が良い可能性もあります。そのため、より業務の方々にとって納得感のある評価用データセットを用意し、それを使ってRAGを試行錯誤していくことが重要です。
サンプル就業規則
(前文)
この就業規則は、会社と社員が相互信頼のうえに立ち、社員の豊かな生活の創造と社業の発展を目的として制定されたものであって、会社と社員はそれぞれの担当する経営、職務について責任をもって積極的にかつ誠実にその職務を遂行することにより、この目的を達成するものとする。
第1章 総 則
(目的)
第1条 この就業規則(以下「規則」という。)は、株式会社○○○○(以下「会社」という)の社員の服務規律、労働条件その他の就業に関する事項を定めたものである。2.この規則に定めのない事項については、労働基準法その他関係法令の定めるところによる。
(規則の遵守)
第2条 会社および社員は、各々誠実にこの規則に従って秩序を維持し、共に協力して社業の発展、労働条件の向上に努めなければならない。
(社員の定義)
第3条 この規則において社員とは、第4条に定める手続によって会社に雇用された者をいい、パートタイマーその他臨時に雇用する者は含まない。
第2章 人 事
(採用)
第4条 会社は就業を希望する者の中から選考試験に合格し所定の手続を経た者を社員として採用する。選考試験の方法等は会社において定める。
(採用決定者の提出書類)
第5条 採用を決定された者は、採用後2週間以内に次の書類を提出することとする。
評価結果Ⅱ
次に、パラメータ①とパラメータ②を固定した状態で、パラメータ③を見てみます。
| ②分割した規定文書の入力数& ①検索エンジンに登録する 規定文書の長さ |
約4,000文字分&250 | ||
|---|---|---|---|
| ③検索方法 | ベクトル | ハイブリッド | セマンティック ハイブリッド |
| Retrieval Correctness | 4.56 | 4.76 | 4.69 |
| Answer Correctness | 4.00 | 4.05 | 4.19 |
| Answer Correctnessの 4、5の割合(正答率) |
0.74 | 0.76 | 0.85 |
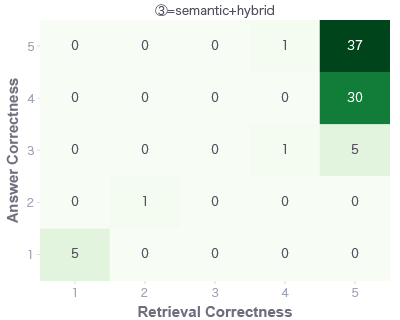
表で見ると、Retrieval Correctnessはハイブリッド検索の方が微差で良いが、Answer Correctnessはセンティックハイブリッド検索の方が良い結果となり、正答率としても85%となりました。もう少し詳細にヒートマップで確認します。
Retrieval Correctnessはいずれもほとんど5です。しかし実は、ある質問で、セマンティックハイブリッド検索時にCognitive Searchの内部エラーが発生しました。その質問の評価を1として計算しているため、この微差が出ているともいえそうです。Retrieval Correctnessはほとんど同じ平均スコアになった一方で、Answer Correctnessは、セマンティックハイブリッド検索の方が良いです。正答率にも差があります。
これは、「確かにいずれもRetrieval Correctnessがほとんど5ではあるが、ハイブリッド検索とセマンティックハイブリッド検索の取得してくる文書が異なり、ground truthと同じ回答ができるような文書を取得できているのはセマンティックハイブリッド検索の方であり、それにより正答率が高くなった」といえます。
ここからいえることは、その文書の差がRetrieval Correctnessでは全てスコア5のうちに収まってしまっているので、まだまだRetrieval Correctnessの改善の余地はありそうということです。

評価結果Ⅲ
最後に、パラメータ①、パラメータ②、パラメータ③を評価結果Ⅱまでで一番良かったパラメータで固定した上で、パラメータ④を変えたRAGを評価してみます。
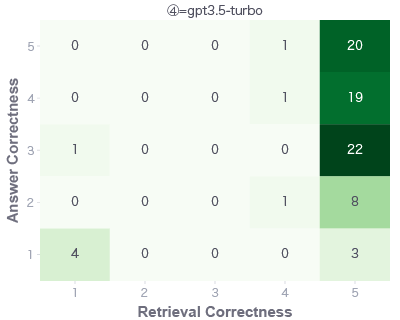
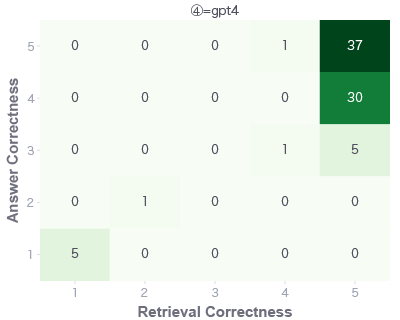
今回はGPT-4が最も良い結果となりました。
GPT4-Turboとはあまり差がなさそうですがGPT-3.5-Turboとはやはり明確な差があります。
| ②分割した規定文書の入力数& ①検索エンジンに登録する 規定文書の長さ& ③検索方法 |
約4,000文字分&250& セマンティックハイブリッド |
||
|---|---|---|---|
| ④LLM | gpt3.5-turbo | gpt4 | gpt4-turbo |
| Retrieval Correctness | 4.71 | 4.69 | 4.74 |
| Answer Correctness | 3.45 | 4.19 | 4.09 |
| Answer Correctnessの 4、5の割合(正答率) |
0.51 | 0.85 | 0.79 |
ヒートマップで詳細を見てみると、GPT-3.5-Turbo(左)は右下範囲の数値が増えています。これは、適切な文書の情報を与えられても、うまく回答を生成できておらず、ハルシネーションが起きているといえます。
(余談)
「パラメータ④のLLMを変えただけなのに、なぜRetrieval Correctnessの値が異なるの?パラメータ①②③はどれも同じで、検索エンジンが取得してくる文書は同じはずだからRetrieval Correctnessのスコアは同じ値でないとおかしいでしょ?」と気づいた方がいらっしゃるかもしれません。
OpenAIが提供してくれているAPIにはtemperatureというパラメータがあります。このパラメータは高いほどLLMの回答がランダムになり、低いほど決定論的になるというものです。そして、様々な記事でこのtemperatureを0にすることで同じ回答を得ることができるとされていますが、実は違います。
以下を見ていただくと後半の方が微妙に違うことがわかるかと思いますが、temperatureを0にしても必ずしも同じ文章を得られるとは限りません。
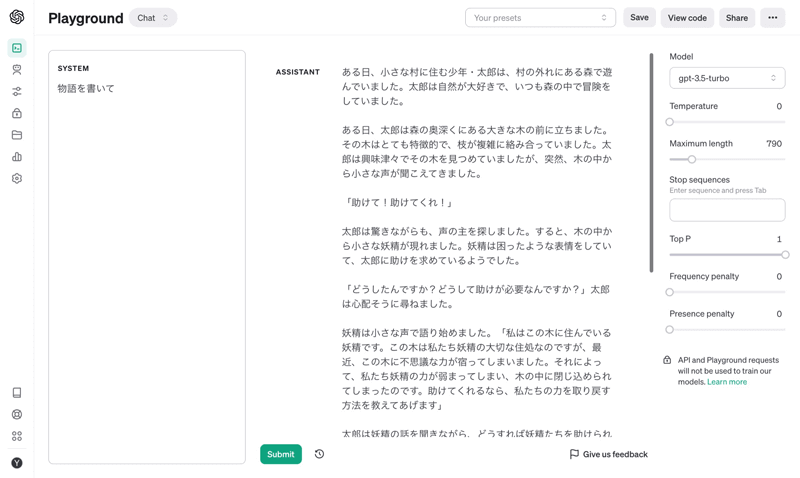
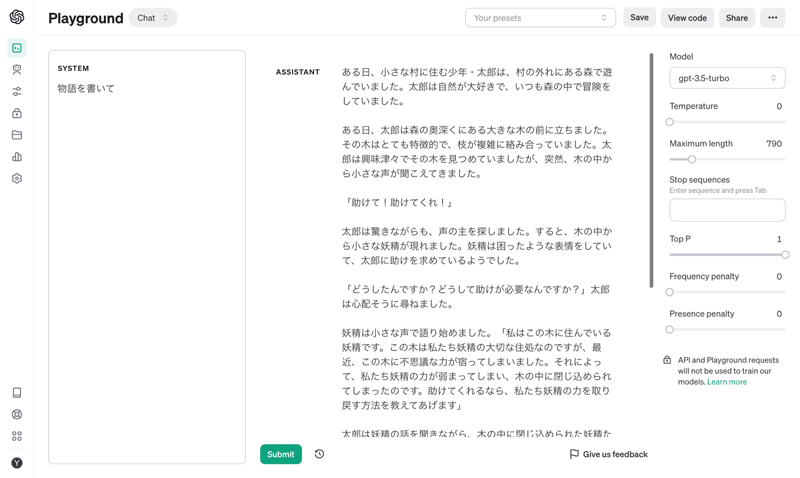
そのため、今回の評価用AIでもtemperature=0としているものの、微妙に評価に誤差が生じています。今回は評価結果ⅢのRetrieval Correctnessにて4.69〜4.74と0.05ほどの差が出ました。
なお、現在(2024年1月16日時点)、「seed」というパラメータがOpenAI APIにベータ版のパラメータとして追加されています。これはLLMの回答に一貫性を持たせるように設計されたパラメータのようです。今後はこちらのパラメータを指定することで評価にも再現性を持たせることができそうです。
このような理由により、今回の結果はいずれも誤差を抱えている結果となっています。本来はそれぞれのRAGを3回ほど評価し平均した結果を出したかったのですが、かなりコストがかかってしまうのでこのくらいで留めました。
評価結果まとめ
今回のパラメータの範囲では社内規程集RAGは、「250文字で分割した文書を検索エンジンに登録し、セマンティックハイブリッド検索で取得した、質問と関連する4,000文字分(16文書)の情報をLLMに入力した上で、GPT-4に回答してもらう」が最も良い精度になることが分かりました!
ただし、こちらの結果はあくまでラックの社内規程集RAGと今回の評価用データセットでの結果です。全てのRAGに当てはまる最適なパラメータは存在しません。RAGごとに評価用データセットを用意し、評価していく必要があります。
RAGの評価をやってみて
今回は、社内規程集RAGを使って評価の流れを学びました。
取り組んだことは以下です。
- 1.評価用データセットの作成
- 2.RAG評価ライブラリの調査
- 3.評価用AIのプロンプト作成と人手評価との比較による妥当性の確認
- 4.社内規程集RAGの自動評価
1. 評価用データセットの作成
今回は各規程の所管部署に作ってもらいました。データセットを作る際は、ルールを決めて作っていく必要があります。プロフェッショナルだからこそ、文書に書いていない専門用語で質問を作ってしまったり、回答に潜在知識が入ってしまったりします。
また、「こんな質問は業務でしないよ」というデータセットで評価しても意味がありませんので、実際にRAGを使っていく業務の方々の納得感が必要です。
場合によっては、LLMで質問と回答のペアを生成するという方法もあります。この方法を取ることで、人間特有のバイアスは減りますが、人間らしくない質問も生成されるため、補助的に使うことが望ましいかもしれません。
2. RAG評価ライブラリの調査
今回は特に取り上げませんでしたが、ここも結構な時間がかかりました。有名なものですと、ragasといったRAG評価に特化したオープンソースライブラリもあります。他にもあるのですが、いずれもこれから開発が進んでいくといったライブラリが多いです。
ただ、そういったライブラリは活動が活発で、比較的近いうちに誰でも使えるようになると思われます。ビジネスのニーズに沿った評価指標を選択して、そういったライブラリにあればそれを使う。なければ今回のような評価用AIを作っていく、というのがいいかもしれません。
3. 評価用AIのプロンプト作成と人手評価の比較による妥当性の確認
今回は評価用AIのプロンプトの作成と、本当にそのプロンプトを入力したLLMが、もっともらしいスコアを出力してくれるかという妥当性を、人手評価との比較により確認しました。評価用AIのプロンプトの作成自体も試行錯誤が必要でした。こちらも評価用データセットとは別に10個ほどの質問と回答を用意して、試行錯誤(プロンプトエンジニアリング)していく方が良いでしょう。
また、最初の人手評価との比較のため、5段階(1〜5)といった人でも解釈・評価しやすいスコアリングが有効です。そして、人手評価がしやすいガイドラインを丁寧に作る必要があります。
今回自作したRetrieval Correctnessは改善の余地がありました。また、評価自体のコストもRAGを試行錯誤していく上で考えていく必要があります。80問のRAGでの回答生成と評価で1回数千円ほどコストがかかりました......。今後はオープンソースモデルでの評価なども試行したいなと思っています。
4. 社内規程集RAGの自動評価
今回は簡易的なパラメータをいくつか決めて自動評価の比較をしましたが、最近はすでに様々なRAGのアーキテクチャが提案されています。そういったアーキテクチャも、ある文書群を扱うRAGに対しては有効でも別の文書群を扱うときには有効ではないかもしれません。そもそも評価できないとどういったアーキテクチャが良いのかわからないです。
RAG同士の比較がスムーズにできる環境を整えるため、今回は現状あるオープンソースなどを調査しながら、試しに社内規程集RAGを自動評価してみました。
実際は、試行した数あるRAG中のTop3を自動評価で決め、Top3の中でどれが良いかは人手評価をして納得感を確保した上で、最終的なアーキテクチャを決める、といった方法も一つの手かなと思います。
「LAC AI Day 2023」の講演動画を公開中
本記事でご紹介したRAGの評価について、ラックのイベント「LAC AI Day 2023」でもご紹介しました。当日の動画を公開しておりますので、ぜひご視聴ください。
【特別公開】LAC AI Day 2023 講演動画
さいごに
ここまで読んでいただきありがとうございました。検証自体は2023年10・11月ごろに実施しておりますが、LLMの分野は非常に進みが速く、皆さんがこれを読む頃にはもうすでに古い方法になっている可能性も否めません。
また、実際に業務・事業で使っていくRAGの検証ともなれば更に色々な人の協力が必要で、今回記した事だけでは考慮事項が足りないことも多々あると思います。が、少しでも皆さんのRAGそのものやRAG評価の理解の一助になれば幸いです。
私も置いていかれないよう、引き続き調査・検証を進めていきたいと思っています。
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- AIエージェント
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR