
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- AIエージェント
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR











クラウドセキュリティの需要は急速に拡大しており、米国の調査会社によると2024年第2四半期には市場が42%成長したという報告もあります。これは海外の話にとどまらず、国内にいる私たちも、クラウド上のシステム開発と運用時のセキュリティ監視を行う「Prisma® Cloud」を導入済みのお客様からの問い合わせが増えていると感じています。
導入フェーズを終えた今、運用負荷を軽減する手段を模索している方も多いのではないでしょうか。この記事では、Prisma® Cloudの運用負荷を軽減するための具体的な方法をご紹介します。
なお、今回はPrisma® Cloud APIを活用するための基盤コードを作成し、現在実行中の定型作業のフローチャート化と効率化を行う流れで、Prisma® Cloudの運用業務をコード化する手法をご説明します。また、ChatGPTを活用したコード生成とテストの事例もありますので、ぜひ最後までご覧ください。
事前準備
この記事では、Prisma® Cloud RESTAPIを活用した処理をご紹介するので、事前に実行環境をご用意ください。
準備するもの
- Python3.11が実行可能な環境
- Prisma® CloudのテナントID
- ログイン用のIDとパスワード
上記3つの準備が完了したら、初期ログインのコードを用意します。内容はほぼ定型文で下記のような内容です。prismacloud.apiを利用して、RESTAPIを実行するトークンを取得するための処理です。
import requests
import urllib.parse
from prismacloud.api import pc_api, pc_utility
# --ユーザカスタムコマンドライン引数-- #
parser = pc_utility.get_arg_parser()
args = parser.parse_args()
# --初期化&ログイン-- #
settings = pc_utility.get_settings(args)
pc_api.configure(settings)
def alt_login():
url = urllib.parse.urljoin('https://' + pc_api.api, 'login')
headers = { 'Content-Type': 'application/json' }
body_params = {
"prismaId": pc_api.name,
"username": pc_api.identity,
"password":pc_api.secret
}
response = requests.post(url, headers=headers, json=body_params, verify=pc_api.verify)
token = response.json()['token']
pc_api.token = token
print(token)
print()
alt_login()
トークンの取得には対象テナントの情報が必要なので、Pythonのホームディレクトリ直下に以下の内容でcredentials.jsonも用意してください。なお、右側はコメントなので、実行時には削除してください。記載フォーマットを変更することでアクセスキー利用とすることも可能です。
{
"api": "https://api.xx.prismacloud.io/",//Prisma Cloudのテナントリージョンを指定
"name": "xxxxxxxx", //Prisma CloudのテナントID
"username": "xxx@example.com", //処理を実行させたいユーザのID
"password": "xxx" //処理を実行させたいユーザのパスワード
}
なお、上記で指定するのはPaloalto Hubではなく、Prisma® Cloud本体のログインIDとパスワードである点に注意してください。以下の図で示した、レガシーログインコンソールにログインするIDとパスワードになります。
設定が正しければ、このようにコマンド発行用のトークン情報を取得できます。

定型作業のフローチャート化と効率化
さて、ここまで準備できれば、あとはどの業務を効率化するかを検討しましょう。この記事では、IAM系アラートで検知されたEC2インスタンスへのタグ情報付加を自動化します。
アラート一覧画面で同一の資源で複数のアラートが検知されているのに、アセットのタグでフィルタリングをかけるとなぜか表示されるアラートの数が激減することを、不思議に思ったことはありませんか?これはなぜなのでしょうか。
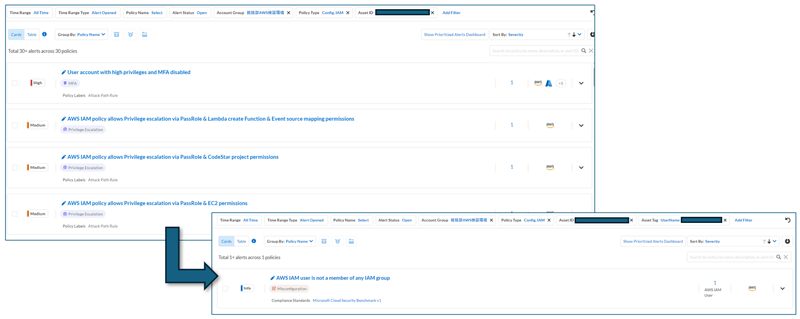
その理由は、IAM系のアラートは資源のタグ情報を拾わない仕様だからです(2024年12月現在)。ですが、特に大量に出力されがちなIAM系の権限アラートを、タグでフィルタリングできないと不便ですよね。ベンダーに機能改善のリクエストをしても、すぐに実装されるわけではなく、オペレーション作業が待ってくれるわけでもありません。
そこで、自前でインベントリ上のタグ情報をIAMアラートに付加するコードを作ってみましょう。これが実現できれば、過検知を起こしがちな高権限アラートをタグで分類でき、優先順位の切り分け作業が大幅に楽になるはずです。
では、具体的にどうすればアラートにタグを付与できるのか説明します。まずは、インベントリ上にあるタグ情報を自分で拾いに行く必要がありますね。どのアセットのタグを拾うかは、IAMアラート上のインスタンスIDがあれば大丈夫でしょう。つまり、下記のフローで実現します。
解決策のフロー
- IAMアラートからインスタンスIDを抽出
- インスタンスIDを元に、インベントリからインスタンスのユニークキーを取得
- ユニークキーを元に、インベントリからタグ情報を個別取得
- 上記情報を突合し、アラートごとにタグ情報を付加
ChatGPTを活用したコード生成とテストの事例
続いて、コードを生成します。まず、どのRESTAPIを組み合わせればよいかを考えましょう。下記ページから使えそうなAPIを検討します。
Welcome to the Prisma Cloud APIs | Develop with Palo Alto Networks
今回は、以下のAPIを用いて実装します。
利用するAPI
- アラート一覧の収集
(List Alerts V2 - POST | Develop with Palo Alto Networks) - ユニークキーの収集
(Resource Scan Info V2 - POST | Develop with Palo Alto Networks) - タグ情報の収集
(Get Asset | Develop with Palo Alto Networks)
それぞれのAPIのページを開き、リクエスト構造を確認します。アラート一覧の収集であれば、構造は下記の通りです。
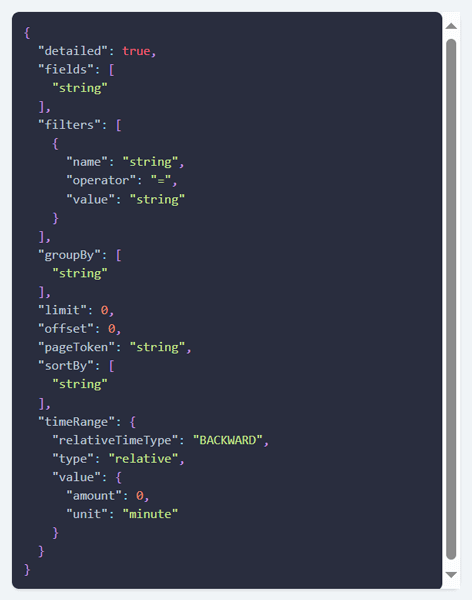
フィルタ条件はpolicy.type=iam、alert.status=open、resource.type=EC2 Instanceで良さそうです。では、早速試してみましょう。下記のように、アラート情報の一覧が取得できました。
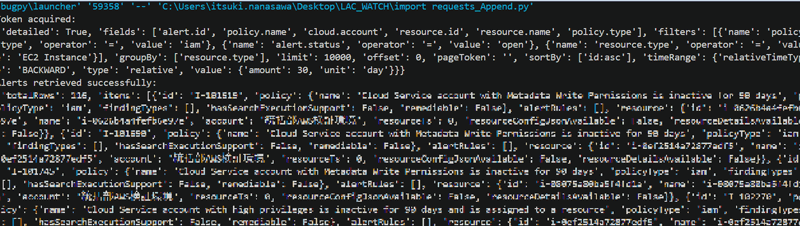
JSONは便利ですが、どうしても読みにくいと感じることがありますよね。そこで、必要な情報だけをCSVに出力しなおしていきます。これまでは、ここの情報整理に多くの時間がかかり大変だったのですが、その部分はChatGPTにお願いしてしまいましょう。ここでは、CSVに出力して、その後必要な情報を取得するように再修正をお願いしてみました。
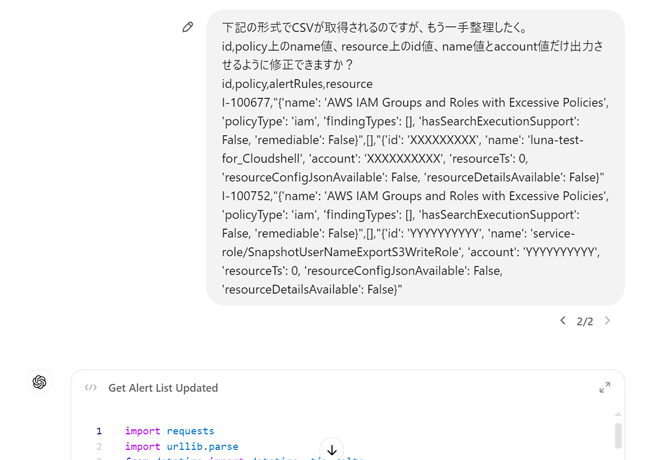
すると、以下のようなコードができました。
# --IAM系アラート取得処理
# --実行日から30日前までに発行されたIAMアラート:オープン中:EC2が対象のものを取得
# --alerts_output.csvに出力
import requests
import urllib.parse
from datetime import datetime, timedelta
from prismacloud.api import pc_api, pc_utility
import json
import pandas as pd
# --ユーザカスタムコマンドライン引数-- #
parser = pc_utility.get_arg_parser()
args = parser.parse_args()
# --初期化&ログイン-- #
settings = pc_utility.get_settings(args)
pc_api.configure(settings)
def alt_login():
url = urllib.parse.urljoin('https://' + pc_api.api, 'login')
headers = {'Content-Type': 'application/json'}
body_params = {
"prismaId": pc_api.name,
"username": pc_api.identity,
"password": pc_api.secret
}
response = requests.post(url, headers=headers, json=body_params, verify=pc_api.verify)
if response.status_code == 200:
token = response.json()['token']
pc_api.token = token
print("Token acquired:")
return token
else:
print("Error acquiring token:", response.status_code, response.text)
raise Exception("ログイン失敗")
def get_alerts(api_token):
api_url = urllib.parse.urljoin('https://' + pc_api.api, '/v2/alert')
headers = {
'Content-Type': 'application/json',
'x-redlock-auth': api_token
}
body_params = {
"detailed": True,
"fields": [
"alert.id",
"policy.name",
"cloud.account",
"resource.id",
"resource.name",
"policy.type"
],
"filters": [
{
"name": "policy.type",
"operator": "=",
"value": "iam"
},
{
"name": "alert.status",
"operator": "=",
"value": "open"
},
{
"name": "resource.type",
"operator": "=",
"value": "EC2 Instance"
}
],
"groupBy": [
"resource.type"
],
"limit": 10000,
"offset": 0,
"pageToken": "",
"sortBy": [
"id:asc"
],
"timeRange": {
"relativeTimeType": "BACKWARD",
"type": "relative",
"value": {
"amount": 30,
"unit": "day"
}
}
}
print(body_params)
response = requests.post(api_url, headers=headers, json=body_params, verify=pc_api.verify)
if response.status_code == 200:
print("Alerts retrieved successfully:")
data = response.json()
# JSONデータを整理して必要な項目を抽出
alerts = data.get('items', []) # 'items'キーにデータが含まれていると仮定
processed_alerts = []
for alert in alerts:
alert_id = alert.get('id', '')
policy_name = alert.get('policy', {}).get('name', '')
resource = alert.get('resource', {})
resource_id = resource.get('id', '')
resource_name = resource.get('name', '')
account = resource.get('account', '')
processed_alerts.append({
'id': alert_id,
'policy_name': policy_name,
'resource_id': resource_id,
'resource_name': resource_name,
'account': account
})
# CSVに変換して保存
if processed_alerts:
df = pd.DataFrame(processed_alerts)
output_file = 'alerts_output.csv'
df.to_csv(output_file, index=False)
print(f"Alerts have been saved to {output_file}")
else:
print("No alerts found in the response.")
else:
print("Error retrieving alerts:", response.status_code)
print(response.text)
# メイン処理
try:
api_token = alt_login() # トークンを取得
get_alerts(api_token)
except Exception as e:
print("An error occurred:", str(e))
この勢いで、アセット情報一覧の取得もしてみましょう。リクエスト構造が以下のような内容なら、フィルタはresource.type=EC2 Instanceだけで良さそうです。早速実行してみます。
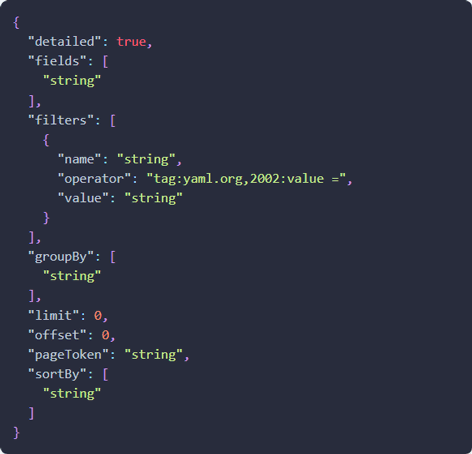
なかなかいい感じに取得できました。同じようにChatGPTにデータの整形を依頼してみます。
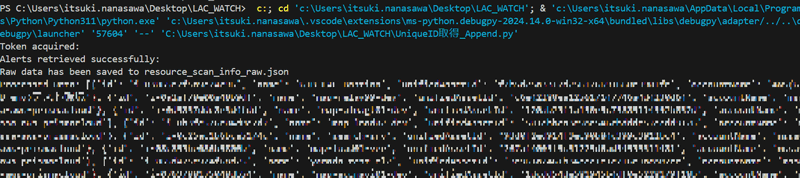
下記のようなコードができました。
# --インスタンスID取得処理
# --インベントリ上のEC2インスタンス情報を取得→resource_scan_info_raw.jsonに出力
# -- resource_scan_info_raw.jsonを整理→resource_scan_info.csvに出力
import requests
import urllib.parse
from datetime import datetime, timedelta
from prismacloud.api import pc_api, pc_utility
import json
import pandas as pd
# --ユーザカスタムコマンドライン引数-- #
parser = pc_utility.get_arg_parser()
args = parser.parse_args()
# --初期化&ログイン-- #
settings = pc_utility.get_settings(args)
pc_api.configure(settings)
def alt_login():
url = urllib.parse.urljoin('https://' + pc_api.api, 'login')
headers = {'Content-Type': 'application/json'}
body_params = {
"prismaId": pc_api.name,
"username": pc_api.identity,
"password": pc_api.secret
}
response = requests.post(url, headers=headers, json=body_params, verify=pc_api.verify)
if response.status_code == 200:
token = response.json()['token']
pc_api.token = token
print("トークン取得成功:")
return token
else:
print("Error acquiring token:", response.status_code, response.text)
raise Exception("ログイン失敗")
def get_alerts_and_save(api_token):
api_url = urllib.parse.urljoin('https://' + pc_api.api, 'v2/resource/scan_info')
headers = {
'Content-Type': 'application/json; charset=UTF-8',
'Accept': '*/*',
'x-redlock-auth': api_token
}
body_params = {
"detailed": True,
"fields": [
"resource.name"
],
"filters": [
{
"name": "resource.type",
"operator": "=",
"value": "EC2 Instance"
}
],
"groupBy": [
"cloud.service"
],
"limit": 10000,
"offset": 0,
"sortBy": [
"id:asc"
]
}
response = requests.request("POST", api_url, headers=headers, json=body_params)
if response.status_code == 200:
print("Alerts retrieved successfully:")
data = response.json()
# JSON全体を保存
raw_output_file = 'resource_scan_info_raw.json'
with open(raw_output_file, 'w', encoding='utf-8') as raw_file:
json.dump(data, raw_file, ensure_ascii=False, indent=4)
print(f"Raw data has been saved to {raw_output_file}")
# 保存したJSONを読み込み
with open(raw_output_file, 'r', encoding='utf-8') as raw_file:
loaded_data = json.load(raw_file)
# 必要なフィールドのみを抽出
resources = loaded_data.get('resources', []) # 'resources'キーに合わせる
if not resources:
print("No resources found in the data. Check the structure of the JSON.")
return
processed_data = []
for item in resources:
processed_data.append({
'id': item.get('id', ''),
'name': item.get('name', ''),
'unifiedAssetId': item.get('unifiedAssetId', ''),
'accountName': item.get('accountName', '')
})
# 抽出データをCSVに保存
output_file = 'resource_scan_info.csv'
if processed_data:
df = pd.DataFrame(processed_data)
df.to_csv(output_file, index=False, encoding='utf-8')
print(f"Processed resource scan info has been saved to {output_file}")
# 再度保存したデータを読み込み
read_df = pd.read_csv(output_file, encoding='utf-8')
print("Loaded processed data:")
print(read_df.head())
else:
print("No data was processed to save to CSV.")
else:
print("Error retrieving resources:", response.status_code)
print(response.text)
# メイン処理
try:
api_token = alt_login() # トークンを取得
get_alerts_and_save(api_token)
except Exception as e:
print("An error occurred:", str(e))
次は、突合処理に進みます。これはシンプルなCSVファイル処理なので、まるっとAIに投げてしまいましょう。IAMアラート一覧上のインスタンスIDとアセット一覧上のインスタンスIDを突合させ、unifiedAssetId(Prisma® Cloud上一意なアセットID)だけを抜き出します。
# --突合処理
# -- alerts_output.csv とresource_scan_info.csvを突合
# -- 重複インスタンスIDを対象としたunifiedAssetIdを抽出→alerts_output_with_unifiedAssetId.csvに出力
import pandas as pd
def merge_unified_asset_id(alerts_file, resource_file, output_file):
# Load the CSV files
alerts_df = pd.read_csv(alerts_file)
resource_df = pd.read_csv(resource_file)
# Ensure that only the first column (ID) and unifiedAssetId are used from the resource file
resource_df = resource_df[['id', 'unifiedAssetId']]
# Perform a merge on the specified condition
merged_df = alerts_df.merge(resource_df,
left_on='resource_id',
right_on='id',
how='left')
# Add unifiedAssetId to the original alerts_output_統合用 DataFrame
alerts_df['unifiedAssetId'] = merged_df['unifiedAssetId']
# Save the result to a new CSV file
alerts_df.to_csv(output_file, index=False)
print(f"Merged file saved to {output_file}")
# File paths
alerts_file_path = 'alerts_output.csv'
resource_file_path = 'resource_scan_info.csv'
output_file_path = 'alerts_output_with_unifiedAssetId.csv'
# Run the function
merge_unified_asset_id(alerts_file_path, resource_file_path, output_file_path)
続いて、タグ情報の収集APIに取得したunifiedAssetIdを投げてテストしてみます。良い感じに取れましたね。ちょうど、Prisma® Cloudテストのために作ったProxyサーバが引っかかりました。
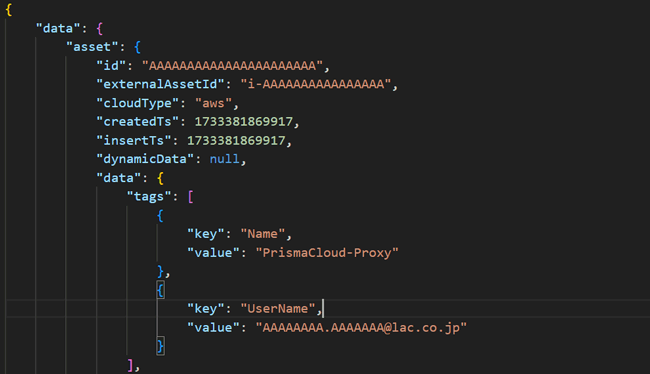
では、またAIに働いてもらいましょう。上記テストに使ったコードに、下記処理を追加してもらいます。
- ①unifiedAssetIdの値を変数に、一覧ファイルからキーにして全件の問い合わせをかけてもらう
- ②出力されたデータからasset_idとasset_data_tags情報だけを抜き取る
- ③一覧ファイルと結果を突合しマージ
でき上がったコードはこちらです。
# --タグ取得処理
# --alerts_output_with_unifiedAssetId.csv上のunifiedAssetIdごとにリクエスト発行
# --タグ付加したアラート情報をenriched_alerts_output.csvに出力
import requests
import urllib.parse
import json
import pandas as pd
from prismacloud.api import pc_api, pc_utility
# --ユーザカスタムコマンドライン引数-- #
parser = pc_utility.get_arg_parser()
args = parser.parse_args()
# --初期化&ログイン-- #
settings = pc_utility.get_settings(args)
pc_api.configure(settings)
def alt_login():
url = urllib.parse.urljoin('https://' + pc_api.api, 'login')
headers = {'Content-Type': 'application/json'}
body_params = {
"prismaId": pc_api.name,
"username": pc_api.identity,
"password": pc_api.secret
}
response = requests.post(url, headers=headers, json=body_params, verify=pc_api.verify)
if response.status_code == 200:
token = response.json()['token']
pc_api.token = token
print("トークン取得成功:")
return token
else:
print("Error acquiring token:", response.status_code, response.text)
raise Exception("ログイン失敗")
def process_unified_asset_ids(api_token, csv_file, output_csv, enriched_csv):
# CSVファイルを読み込む
df = pd.read_csv(csv_file)
# unifiedAssetIdの重複を排除
unique_asset_ids = df['unifiedAssetId'].drop_duplicates()
all_tags = []
for asset_id in unique_asset_ids:
api_url = urllib.parse.urljoin('https://' + pc_api.api, 'uai/v1/asset')
headers = {
'Content-Type': 'application/json; charset=UTF-8',
'Accept': '*/*',
'x-redlock-auth': api_token
}
body_params = {
"assetId": asset_id,
"type": "asset",
}
response = requests.request("POST", api_url, headers=headers, json=body_params)
if response.status_code == 200:
print(f"Alerts retrieved successfully for assetId: {asset_id}")
data = response.json()
tags = data.get("data", {}).get("asset", {}).get("data", {}).get("tags", [])
for tag in tags:
all_tags.append({
"assetId": asset_id,
"key": tag.get("key"),
"value": tag.get("value")
})
else:
print(f"Error retrieving resources for assetId {asset_id}: {response.status_code}")
print(response.text)
# 結果をタグごとに保存
tags_df = pd.DataFrame(all_tags)
# 入力データとタグデータを統合
enriched_df = df.merge(tags_df, left_on='unifiedAssetId', right_on='assetId', how='left')
# 統合データを保存
enriched_df.to_csv(enriched_csv, index=False, encoding='utf-8')
print(f"Enriched data saved to {enriched_csv}")
# メイン処理
try:
api_token = alt_login() # トークンを取得
csv_file = 'alerts_output_with_unifiedAssetId.csv' # 入力CSVファイル名
output_csv = 'tags_output.csv' # タグの中間出力ファイル名
enriched_csv = 'enriched_alerts_output.csv' # 統合出力ファイル名
process_unified_asset_ids(api_token, csv_file, output_csv, enriched_csv)
except Exception as e:
print("An error occurred:", str(e))
こちらも良い感じに取れました。Keyがタグ情報、Valueが実際に設定されている値です。

これで、IAM系のアラートでもタグのフィルタリングができるようになりました。ここまでくれば、タグを元にアラートを分類するのはExcel上のフィルタ機能で十分です。分類後は、下記APIを用いて一括Dismissする処理を追加開発しても良いかもしれません。
Dismiss Alerts | Develop with Palo Alto Networks
実際に実装したものが下記の通りです。これで、手動での切り分けからアラートDismissまで自動化できました。

このように、リクエストによる機能拡張が追いつかない場合でも、APIを活用すれば自前で課題を解決できます。これまでは、取得したデータの整形や整理、コード化に手間がかかりましたが、生成AIの活用で効率化できる時代になりました。
とはいえ、今回のコードにはまだ改善の余地があります。例えば、これまで取得したタグ情報の一覧をローカルに保存しておけば、毎回すべてのデータを問い合わせる必要がなくなります。また、特定のクラウドアカウントで生成されたアラートのみを対象とする機能を追加するのも有効でしょう。さらに、収集するアラートを「重要度が高以上」に制限することで、より実務に即した運用が可能になります。
このような改良を加えながら、実際に作成したコードを元にPDCAサイクルを回すことで、業務に最適化された自動化が実現できるはずです。
さいごに
この記事では、RESTAPIを実際に動かせるコードと、処理が自動化される流れをご覧いただきました。自動化を進めることで、作業効率が大幅に向上し、業務の精度も高まります。
ラックでは、自動化だけでなくシステム全体の最適化を目指した手厚いサポートを提供しています。Pythonだけでなく、Power Automateを活用した処理の自動化も可能です。ご興味がある方は、ぜひラックのクラウドセキュリティ統制支援サービスをご検討ください。

この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- AIエージェント
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR