
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- AIエージェント
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR











イノベーション推進部AIプロダクト開発グループの南です。
ラックは、明治大学の高木友博研究室と、ビジネスへの応用を目的とした、AIの先端技術研究を共同で行っています。
その共同研究のひとつの成果として、「ResBit: Residual Bit Vector for Categorical Values」というタイトルの論文を、「arXiv(アーカイブ)」※1に投稿しました。

高木友博教授
(高木友博 研究室 - Meiji University)
※1 物理学や数学、コンピュータサイエンスなどに関する査読前の論文(プレプリント)を公開するWebサイト。
Masane Fuchi, Amar Zanashir, Hiroto Minami, Tomohiro Takagi "ResBit: Residual Bit Vector for Categorical Values"
[2309.17196] ResBit: Residual Bit Vector for Categorical Values
ラックでは、表形式データのデータ生成技術である「合成データ生成」に注目しています。その合成データ生成の方法、ならびにそれに付随する方法に関して新規性のある結果が得られたため、それらを論文としてまとめて公開しました。この論文は、2023年度の人工知能学会全国大会において発表した結果をもとに再構成したものです。また、ICLR 2024にも提出しており、審査待ちの状態です。
本記事では、今回公開した論文がどのような内容なのか解説します。
本論文の概要
本論文の提案事項は以下の2点です。
- 合成データ生成を行う手法であるTRBD(Table Residual Bit Diffusion)
- TRBDの構成にあたり、課題となる既存のカテゴリ値のエンコーディング手法を改善するために構成した手法であるResBit(Residual Bit vector)
TRBDはAI利活用者に対して用途も明確であり、直接的な貢献を果たすものと考えます。その一方で、ResBitは活用のイメージが涌きにくく、副次的な要素のものに見えるかもしれません。しかしながら、ResBitは、AI開発において汎用的に使える技術であるだけでなく、AI利活用者に対して間接的に大きな貢献を果たすアプローチであると考えます。論文の主題がResBitとなっているのも、総合的な貢献度として、TRBDよりResBitのほうが幅広いタスクにおいて応用できると考えています。
以降、本記事では、データ利活用者向けに合成データ生成が貢献する要素について解説し、その後に、AI開発者向けにTRBD・ResBitの技術的側面、および貢献する要素について解説します。
合成データ生成について
2022年6月に画像生成AIであるMidjourneyが登場しましたが、その時期から生成AIというものが世間一般に浸透し始めるようになりました。ChatGPTをはじめとした大規模言語モデル(Large Language Models, LLM)によるテキスト生成、音声や動画の生成など、さまざまなコンテンツがAIにより生成できるようになっています。
実在するデータと同じ構造で異なる値を持つデータを疑似的に生成する技術も存在し、その技術を合成データ(Synthetic Data)といいます。これは生成AIのなかでも世間的な注目度は高くはない技術ですが、「データサイエンティスト スキルチェックリストver.5」のチェック項目にも新規で記載される技術(チェックリスト上は「ダミーデータ生成」と表記)であり、ビジネスへの応用が強く見込まれています。

※2 2023年度版「データサイエンティスト スキルチェックリストver.5」および「データサイエンス領域タスクリスト ver.4」を発表 ニュース|一般社団法人データサイエンティスト協会
合成データ生成を知るうえで重要なキーワードとして「プライバシー強化」「オーバーサンプリング」があります。まずはこの2つの要素について解説し、ユースケースについても紹介します。
プライバシー強化技術
プライバシー強化技術は、さまざまな場面でのデータ利活用がなされることへの期待が高まっています。その一方で、プライバシー侵害に関する多様なインシデントが発生しています。利活用する側においては、そのようなインシデントを防ぐために、収集・蓄積したデータのプライバシー情報をどのように保護し、活用していくかが課題です。
また、プライバシー保護への意識は国内に限った話ではなく、世界全体でも高まってきています。EU圏におけるGDPR(一般データ保護規則)という非常に厳しいプライバシー法が2018年に施行されたことは日本でも話題になりました。アメリカにおいても、カリフォルニア州を皮切りに、2022年頃から各州における動きが活発化しています。さらには中国やタイなど、個人情報保護法が存在しなかったアジア圏においても、同様の動きが加速しています。
このように、企業としての信用問題という観点でなく、法対応という観点からも、プライバシー保護が求められるようになってきています。このプライバシー保護の原則を実現・強化する技術を、総称してプライバシー強化技術といいます。近年提案されている合成データ生成手法は、元データの統計的特徴を保持したままプライバシーに相当するデータを覆い隠すことができるものが多いことから、プライバシーを保護した状態で分析に利用できるといった利点があります。
不均衡データとオーバーサンプリング
不均衡データの分析について、クレジットカードやオンラインバンキングなどの取引データを例に考えます。取引データには、正しい取引(真正取引)と犯罪などによる意図しない取引(不正取引)の2つの取引区分があります。
真正取引の件数に対して、不正取引は非常に少ない件数しかありません。このように区分の比率が極端に偏っているデータを不均衡データといいます。不均衡データの分析を行う場合は、各区分のデータの偏りを補正して、2つの区分のデータ件数の比の均衡性を上げる必要があります。その均衡性を上げるアプローチとしては、以下の2通りがあります。
- 多数派の区分に属するデータを適切な方法で減らすアンダーサンプリング
- 少数派の区分に属するデータを適切な方法で増やすオーバーサンプリング
合成データ生成は、オーバーサンプリングのひとつの手法としても非常に注目を浴びています。
合成データ生成のユースケース
合成データ生成は、プライバシー情報が扱われる状況で用いられます。特にセンシティブな情報を保有する金融・医療の領域においては、すでに多くの活用事例があります。
本論文の技術的側面
ここではTRBDおよびResBitの技術的な側面について概説します。
概説を読んで興味を持っていただけた方は、ぜひともプレプリントを見ていただければと思います。
TRBD
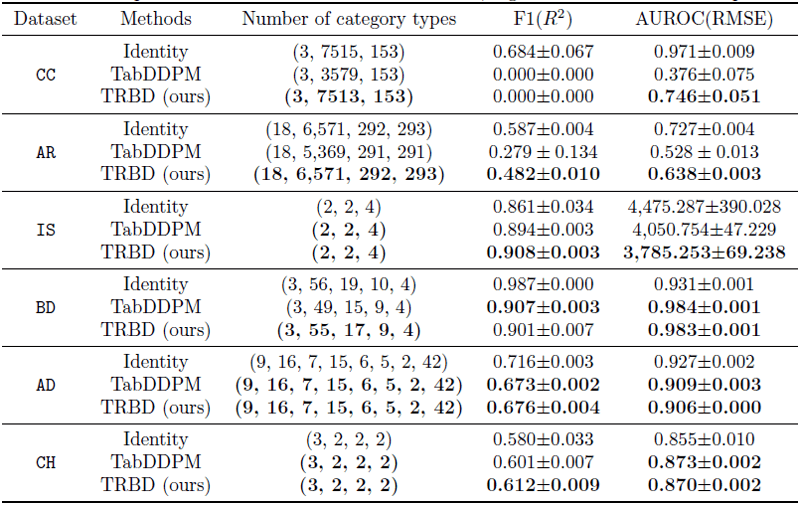
合成データ生成において、現時点でデファクトと呼ばれる手法として、実装面で優位性のあるGANベースのCTGAN(2019)※3、精度面で優位性のある拡散モデルベースのTabDDPM(2022)※4が提案されています。TabDDPMは、数値データに対する前処理はQuantile Transformer、カテゴリデータに対する前処理はOne-Hot Encoderにて実施します。このOne-Hot Encoderによる処理をResBitという手法による処理に置き換えたアプローチがTRDBです。
※3 [1907.00503] Modeling Tabular data using Conditional GAN
※4 [2209.15421] TabDDPM: Modelling Tabular Data with Diffusion Models
TabDDPMとTRDBによる性能を比較した表と、学習時間・データ生成を比較した表を以下に示しますが、いずれもTRDBに優位性のある結果になりました。

ResBit
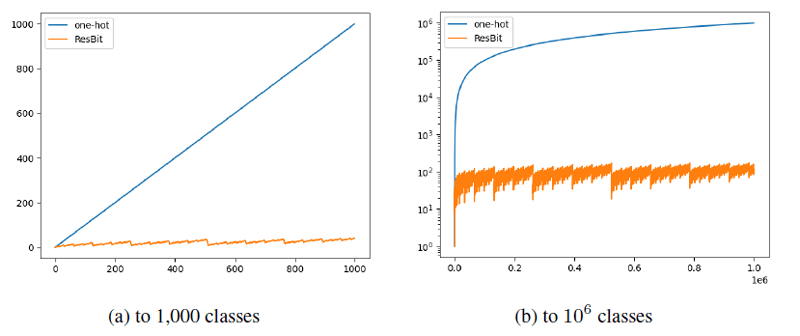
先ほど派生的に登場したResBitですが、これはバイナリ化による表現力の保持する手法(AnalogBits)と、バイナリ化に伴う余分な情報の付与の影響を小さくする手法(Residual Vector Quantization)を組み合わせることで、カテゴリデータの前処理を行う手法です。
One-Hot Encoderはカテゴリ値の種類が増えると、ベクトルの次元が増えてしまいます。これは表現力の面でメリットとなる一方で、空間計算量や時間計算量が増加してしまうデメリットがあります。
ResBitは、One-Hot Encoderにおけるデメリットである計算量を改善しつつ、そのトレードオフとして許容できる程度の精度は保つことを目的として構成されました。ResBitはTabDDPMの困難を解消するために提案された新しいアプローチではあるものの、一般的な画像分類タスクにおける実験においても、TRBDにおいて確認できた性質と同様のものを発揮できており、汎用的な前処理手法としての活用が期待される手法です。

おわりに
合成データ生成は、今後のビジネスにおいてますます重要度が高まる技術になると強く確信しており、そのような時代に向けた実用化への道筋を立てていきたいと考えています。また、大規模言語モデル(LLM)と組み合わせた新しいアプローチによるデータ生成の研究も活発化しており、そのアプローチに対しても追随できるよう取り組んでいきたいと思います。
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- AIエージェント
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR