
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR










クラウドエンジニアリングサービス部の鎌田です。
私は業務でAmazon OpenSearchの以下4つのサービスを利用しています。
- Amazon OpenSearch Service
- Amazon OpenSearch Serverless
- OpenSearch Dashboards
- Amazon OpenSearch UI
先日、Amazon OpenSearchが提供する4つのサービスについて解説する記事を公開しました。今回はその基礎知識を踏まえ、データ連携の手間を大きく削減し、分析をより身近なものにする「ZeroETL接続」に焦点を当てて解説します。大量のデータを、より速く、より手間なく扱うために、Amazon OpenSearchではどのような工夫がされているのかを具体的に見ていきます。
ETLについて
はじめに、ETLとは何を指すのかについて説明します。
ETLとは
ETLとは、データを活用するために欠かせない一連の処理プロセスを指します。社内の別々の場所に保存されているデータを、分析やレポート作成、データウェアハウスへの保存など、目的に合わせて使える形に整え、必要な場所へ届けるための作業です。名称は、抽出(Extract)、変換(Transform)、書き込み(Load)という3つのデータプロセス処理の英語表記の頭文字に由来しています。
3つのデータプロセス処理
Extract(抽出)
Extract(抽出)とは、様々な場所にあるデータを「抜き出す」工程です。対象となるのはデータベースやファイル、ストリーミングデータなど多岐にわたり、ここで必要なデータを過不足なく集められるかが、その後の分析や活用のしやすさを左右します。
Transform(変換)
Transform(変換)とは、抽出したデータを目的の形式や品質に合わせて「加工する」工程です。形式の統一や不要なデータの除外、値の補正などを行い、データの品質を高めます。この工程は要件ごとの調整が多く、ETLの中でも最も手間がかかりやすい部分です。
| 変換作業の例 | 具体的な作業例 |
|---|---|
| データのクレンジング | 欠損値の補完、誤ったデータの修正、重複データの削除など |
| データの整形 | 日付形式の統一、文字列の大文字・小文字変換など |
| データの分割 | 1つのフィールドを複数のフィールドに分ける |
| データの結合 | 異なるテーブルやファイルから関連する情報を結合する |
| データ型の変更 | テキスト形式の数字を数値型に変換するなど |
Load(ロード/書き込み)
Load(ロード/書き込み)とは、変換されたデータを最終的なデータの保存先や利用先に「書き込む」工程です。ここでデータが安定して書き込まれることで、分析やレポート作成を始められる状態が整います。
| 主なロード先 | 説明 | 具体例 |
|---|---|---|
| データウェアハウス | 分析用の大規模なデータベース | Amazon Redshift |
| データレイク | 大量の生データを保存するためのストレージ | Amazon S3 |
| データベース | ほかのアプリケーションが利用する運用データベース | Amazon Aurora、Amazon RDS、Amazon DynamoDB |
| BIツール | レポートやダッシュボードを表示するためのツール | Amazon OpenSearch |
なぜETLが必要なのか
現代のビジネスでは、様々なシステムから大量のデータが生成されますが、これらのデータは形式や粒度が異なり、そのままでは分析に使えません。ETLプロセスを活用することで、データが共通の形式で整理され、分析等にすぐに使える状態になります。
以下でETLプロセス活用メリットの具体例を3つ紹介しますが、活用の幅はこれに限りません。データ活用を本格化させたい方は、ぜひ詳しく調べてみてください。
| 活用メリット | 具体例 |
|---|---|
| 正確な分析とレポート作成 | 質の高いデータに基づいて、信頼性の高い分析結果が得られる |
| データの一貫性 | 異なるシステム間のデータに整合性が保たれる |
| 効率的なデータ活用 | 分析や機械学習モデルの構築など、次のステップへスムーズに移行できる |
ZeroETL接続について
次に、ZeroETL接続について解説します。
ZeroETL接続とは
Amazon OpenSearchのZeroETL接続とは、AWS環境内外のデータソースからAmazon OpenSearch ServiceやAmazon OpenSearch Serverlessへ、専用のETL基盤を構築・管理することなくデータを連携できる機能です。データの取り込みや管理に手間をかけず、運用データを素早く検索・分析・可視化できる点が大きな特長です。
Amazon OpenSearchのZeroETL接続には2つのアプローチがあります。1つは、OpenSearch側でパイプラインを用いてデータを取り込み、自身の環境に保持するデータアクセス方式です。もう1つが、データは元の場所に置いたまま、必要なときに直接参照するクエリアクセス方式(実装としてはダイレクトクエリ方式を用いる)です。ZeroETLではこのクエリアクセス方式が中心となり、データのコピーやロードを最小限に抑えられます。
さらに、可視化や検索性能を高めたい場合には、メタデータのみを保持するマテリアライズドビューや、必要なデータを効率よく参照するカバードインデックスといったアクセラレーション機能を組み合わせることも可能です。ETL処理を繰り返すことなく、データを持たずに活用できる点が、ZeroETL接続の大きな価値と言えるでしょう。
クエリアクセス方式とダイレクトクエリ方式
クエリアクセス方式とは、データをOpenSearch側に取り込まず、元のデータソースに保持したまま参照する考え方です。検索や分析のたびに必要なデータだけを取得するため、ETL基盤の構築やデータの二重管理を避けられる点が特長です。このクエリアクセス方式を実現する代表的な手段が、ダイレクトクエリ方式です。
ダイレクトクエリ方式では、ETL処理が終わったデータを管理しているデータソースに対し、直接Amazon OpenSearch側からクエリを実施することでデータを取得します。ZeroETL接続では、この仕組みをAWSがマネージドで提供するため、利用者はAmazon OpenSearch環境にデータを保存せずに参照できるようになります。お客様環境のデータを自社のAWS OpenSearch環境で閲覧するケースなどに使われます。
ZeroETL接続方式と対応サービス
ZeroETL接続方式はAmazon OpenSearch ServiceおよびServerlessで対応しているサービスが異なります。以下にわかりやすくまとめて整理しました。
| Amazon OpenSearchサービス名 | 方式 | 対応サービス名 |
|---|---|---|
| Amazon OpenSearch Service | ダイレクトクエリ方式 | Amazon S3 |
| データ取り込み方式 | Amazon DynamoDB | |
| Amazon OpenSearch Serverless | ダイレクトクエリ方式 | Amazon Security Lake、Amazon CloudWatch |
| データ取り込み方式 | Amazon DynamoDB |
ZeroETL接続のメリット
Amazon OpenSearchが展開するZeroETL接続は、環境構築を簡便化する非常に有用な機能です。私が実際に業務でAmazon Security LakeのクロスアカウントZeroETL接続を利用した際に感じたメリットを説明します。
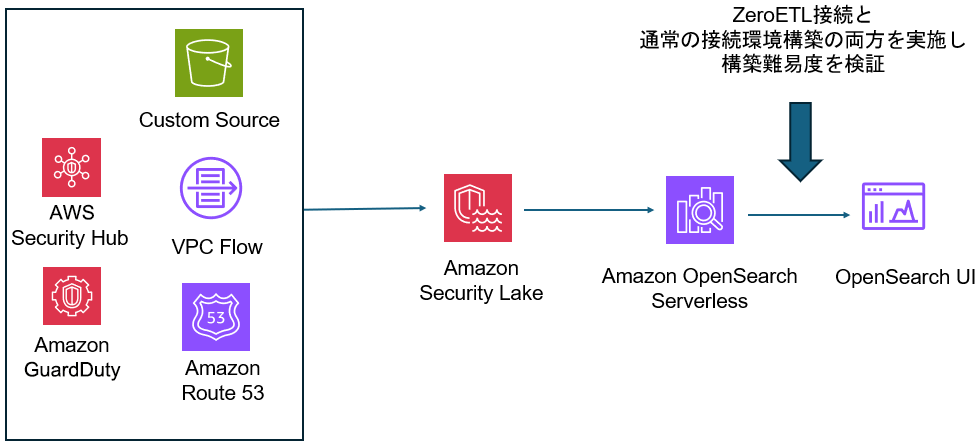
ZeroETL接続を利用して構築した環境
私は業務で、Amazon OpenSearch ServerlessとAmazon Security Lake間のデータ連携環境を構築しました。Amazon Security Lakeは、セキュリティデータ関連のログを自動的に集約し、一元管理できるデータレイクサービスです。Amazon Security Lakeがデフォルトで収集対象としているAWS Security HubやAWS VPC Flowログなどに加えて、利用者が指定したセキュリティログをカスタムソースとして一括管理が可能です。私の最終目標はAmazon Security Lakeで収集した以下ログをAmazon OpenSearch UI上に表示しログの分析ができる環境を提供することでした。
- AWS Security Hubログ
- Amazon Route 53ログ
- Amazon GuardDutyログ
- VPC Flowログ
- Security Lakeカスタムソースログ
なお、Amazon OpenSearch UI上にログを表示する際に、Amazon OpenSearch UIを構築したアカウントにはログを保存せず、ダイレクトクエリを利用して結果を表示する必要がありました。
具体的なメリット
ZeroETL接続利用のメリットは、専用のETL基盤を構築することなくデータ連携を始められる点にあります。複雑な設計や運用を省けるため、構築にかかる時間を大幅に短縮でき、データ活用をすばやく立ち上げられます。
Amazon OpenSearch ServerlessでLakeFormationの接続を開始するためには、以下リソースを作成する必要があります。この中でも特に手間がかかるのがポリシーです。
- OpenSearch UI
- Serverless コレクション
- データアクセスポリシー
- 暗号化ポリシー
- ネットワークポリシー
Amazon Security LakeとAmazon OpenSearch Serverless間でデータを接続するために、以下のサービスを利用します。
- Amazon LakeFormation
- AWS Glue
- Amazon OpenSearch Serverless
上記サービスを安全に接続させるためには、適切なIAMポリシーや信頼ポリシーの設計が不可欠ですが、その作成は容易ではありません。私自身、Amazon OpenSearch ServiceとAmazon Security Lakeのクロスアカウント接続を構築した際、ポリシー設計に苦労しました。AWSの公式資料だけでは自力で構築することができず、サポートに問い合わせながら構築を進めた結果、OpenSearch Dashboards上にデータが表示できるようになるまで1か月近くかかりました。
それに対して、ZeroETL接続を利用したAmazon OpenSearch ServerlessとAmazon Security Lakeの接続は、画面上で3つの設定をするだけでAWSがベストプラクティスを満たすポリシーを作成してくれます。その結果、ZeroETL接続を利用した場合に要した時間はわずか1時間程度でした。
さいごに
今回の記事ではAmazon OpenSearchが展開しているZeroETL接続について、ダイレクトクエリ方式をメインにメリットを紹介しました。ZeroETL接続は、これまで手間がかかっていたデータ連携を劇的にシンプルにする画期的な機能なので、最適なデータ接続方法を利用して快適なAmazon OpenSearch環境利用を実現していただければ幸いです。
また、Amazon OpenSearchは近年大幅なアップデートが実施されており、今後の機能拡充にも期待が高まります。引き続き、AWS公式が発表する情報を追いながら、より快適なAmazon OpenSearch環境を実現していきたいと思います。
プロフィール

鎌田 知里
文系未経験で新卒入社をしたインフラエンジニア2年生(2024年現在)。オンプレNW保守業務を1年経験し、現在はTerraformを利用したAWS構築業務に従事しています。ハリポタは邦訳より原作派。
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR