
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR










昨今、クラウドベンダーが多様化してきたなかで、AWSやGoogle Cloudなど、それぞれのクラウド環境の強みを活かしたいといったニーズが高まっています。
以前、データを一元管理するためにAWS S3上にデータを配置したまま、データ分析に強みのあるBigQueryを利用する検証を行いました。今回も引き続き、データを一元管理するための手法として別の方法を検討してみたので紹介します。
今回のケースではAWS Redshift上で管理しているデータについて、「BigQuery Data Transfer Service」という機能を利用してBigQuery側で処理できるようにデータ転送する検証を行いました。
この手法ではRedshiftにあるデータをBigQuery側へ完全に移行できるため、高性能なデータ分析基盤を利用可能です。また、RedshiftとBigQueryで異なる料金体系になるためコスト面でもメリットがあります。
BigQueryとAmazon Redshift
BigQueryはGoogle Cloudが、Amazon Redshift(以下、Redshift)はAWSが提供するフルマネージド型のデータウェアハウスサービスです。それぞれ、データ処理の方式や料金体、サービスの内容にどのような違いがあるかを比較していきます。
なお、本記事では、従来から提供されているRedshift Provisioned(DC2)を利用して検証を行っています。
BigQueryとRedshiftの比較
BigQueryは、サーバレスアーキテクチャを採用しているため、データの増減に伴うリソースの増減といった管理を行う必要がありません。ただし、課金形態がオンデマンドとなるため、一定のデータ量を処理する場合は利用料が高くなる可能性があります。BigQueryを利用する際は、どのようなワークロードであるかを理解したうえで利用することが重要です。
Redshiftは、クラスタベースのアーキテクチャとサーバレスアーキテクチャのいずれかを選択できます。クラスタベースで管理する場合、ノードのタイプや数を管理するため、より専門的な知識が必要です。サーバレスアーキテクチャとは違い、利用料が想定よりも高くなることがないため、一定のデータ量を処理する場合はRedshiftが適しているのではないかと思います。
上記の他にも比較できる項目について、以下の表にまとめました。
| 項目 | BigQuery | Redshift |
|---|---|---|
| SQL | 標準SQL | 標準SQL |
| インデックス | あり | あり |
| パーティション | あり | なし |
| データ格納方式 | 列指向 | 列指向 |
| クエリの実行環境 | ブラウザUI | コマンドライン |
| 連携可能なストレージ | Google Cloud Storage、Google Drive等 | Simple Storage Service |
| 料金体系 | オンデマンド課金 | 時間課金 |
BigQueryとRedshiftでは料金体系が異なります。ユースケースによってどちらの方が費用対効果の高いサービスかを確かめたうえで、クラウド環境を構築していくことが重要です。
もちろん、各サービスの機能を取捨選択して、より柔軟なクラウド環境にすることも可能なため、本記事がクラウド環境を構築する際の一助になれば幸いです。
検証の概要
RedshiftからBigQueryに、データおよびスキーマを移行する際の構成を作成し、「BigQuery Data Transfer Service」を利用してデータの移行を検証しました。
今回の検証ではRedshiftのデータをソースに指定しますが、「BigQuery Data Transfer Service」では他にもAWS S3やAzure blob Storageなど、指定できるソースは様々です。またデータを移行する際、元データの構成を意識しなくてもGUIの操作から簡単にデータ移行できます。
構成図
「BigQuery Data Transfer Service」を利用してRedshiftからスキーマとデータを移行する場合、以下の図のようにデータの転送が行われます。BigQueryからRedshiftへの通信はGoogle Cloudの公式ドキュメント※1に記載のあるグローバルIPアドレスが利用されるため、セキュリティグループや利用する環境に応じた許可設定が必要です。
※1 Amazon Redshift からスキーマとデータを移行する | BigQuery | Google Cloud 「Amazon Redshift クラスタへのアクセスを許可する」
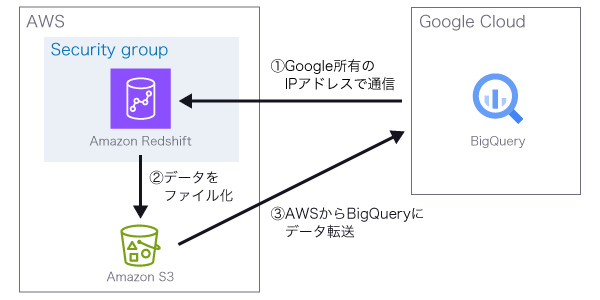
Google Cloud公式ドキュメント※2に記載されている構成図の補足内容についてコメントします。
※2 Amazon Redshift からスキーマとデータを移行する | BigQuery | Google Cloud
補足内容
- Migration agent unloads tables from Redshft. Unload speed is bounded by your cluster configuration.
- Unloaded table data is transferred from S3 to BigQuery.
Tips
1の内容を確認する限り、Redshiftクラスタの構成内容でUnload速度に差異が出るようです。Unload速度は、クラスタのスライス数に応じて処理速度が上がるとのことでした。※3
ノードタイプを変更するとスライス数を増やせるようなので、ユースケースに応じてノードタイプを変更し、Unload速度を向上させると良いでしょう。
Redshift設定
構成図に記載されている通り、AWS側で作成するリソースは大きく分けてRedshiftおよびS3となります。
Redshiftで作成するリソースの設定は、AWS公式ドキュメントに記載されているチュートリアル※4を参考に構築しました。
※4 サンプルデータセットを使用する - Amazon Redshift(https://docs.aws.amazon.com/ja_jp/redshift/latest/gsg/sample-data-load.html)
VPCの作成
Redshiftを作成するためのVPCが必要なため、まずVPCを作成します。手順については、AWS公式ドキュメント※5をご確認ください。
※5 VPC を作成する - Amazon Virtual Private Cloud
{
"Vpcs": [
{
"CidrBlock": "x.x.x.x/x",
"DhcpOptionsId": "dopt-xxxxxxx,
"State": "available",
"VpcId": "vpc-xxxxxxxx",
"OwnerId": "xxxxxxxxxxxx",
"InstanceTenancy": "default",
"CidrBlockAssociationSet": [
{
"AssociationId": "vpc-cidr-assoc-xxxxxxxxxxxxx",
"CidrBlock": "x.x.x.x/x",
"CidrBlockState": {
"State": "associated"
}
}
],
"IsDefault": false,
"Tags": []
}
]
}
サブネットやインターネットゲートウェイの作成手順については、割愛しておりますので適宜作成してください。
IAMユーザの作成と、ポリシーのアタッチ
RedshiftおよびS3操作用のIAMユーザが必要なため、IAMユーザを作成します。
IAMユーザについては、適宜作成いただければと思います。アタッチする権限は以下の通りです。
- AmazonRedshiftFullAccess
- AmazonS3FullAccess
Redshift:クラスタサブネットグループの作成
Redshiftクラスタを作成するためのクラスタサブネットグループが必要なため、クラスタサブネットグループを作成します。手順については、AWS公式ドキュメント※6をご確認ください。
※6 コンソールを使用したクラスターサブネットグループの管理 - Amazon Redshift(https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/managing-cluster-subnet-group-console.html)
{
"ClusterSubnetGroups": [
{
"ClusterSubnetGroupName": "test-cluster-subnet-group-lacwatch",
"Description": "lacwatch",
"VpcId": "vpc-xxxxxxxx",
"SubnetGroupStatus": "Complete",
"Subnets": [
{
"SubnetIdentifier": "subnet-xxxxxxxx",
"SubnetAvailabilityZone": {
"Name": "ap-northeast-1c"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxxxxx",
"SubnetAvailabilityZone": {
"Name": "ap-northeast-1d"
},
"SubnetStatus": "Active"
},
{
"SubnetIdentifier": "subnet-xxxxxxxx",
"SubnetAvailabilityZone": {
"Name": "ap-northeast-1a"
},
"SubnetStatus": "Active"
}
],
"Tags": [],
"SupportedClusterIpAddressTypes": [
"ipv4"
]
}
]
}
Redshift:クラスタの作成
Redshiftクラスタを以下の内容で作成します。手順については、AWS公式ドキュメント※7をご確認ください。
※7 ステップ 1: サンプルの Amazon Redshift クラスターを作成する - Amazon Redshift(https://docs.aws.amazon.com/ja_jp/redshift/latest/gsg/rs-gsg-sample-data-load-create-cluster.html)
{
"Clusters": [
{
"ClusterIdentifier": "test-redshift-cluster-lac-watch",
"NodeType": "dc2.large",
"ClusterStatus": "available",
"ClusterAvailabilityStatus": "Available",
"MasterUsername": "awsuser",
"DBName": "dev",
"Endpoint": {
"Address": "xxxxxxxxx",
"Port": 5439
},
"ClusterCreateTime": "2023-11-21T16:43:29.518000+00:00",
"AutomatedSnapshotRetentionPeriod": 1,
"ManualSnapshotRetentionPeriod": -1,
"ClusterSecurityGroups": [],
"VpcSecurityGroups": [
{
"VpcSecurityGroupId": "sg-073416c0862d826c9",
"Status": "active"
}
],
"ClusterParameterGroups": [
{
"ParameterGroupName": "default.redshift-1.0",
"ParameterApplyStatus": "in-sync"
}
],
"ClusterSubnetGroupName": "test-cluster-subnet-group-lacwatch",
"VpcId": "vpc-xxxxxx",
"AvailabilityZone": "ap-northeast-1a",
"PreferredMaintenanceWindow": "thu:15:30-thu:16:00",
"PendingModifiedValues": {},
"ClusterVersion": "1.0",
"AllowVersionUpgrade": true,
"NumberOfNodes": 1,
"PubliclyAccessible": true,
"Encrypted": false,
"ClusterPublicKey": "xxxxxxxxxx",
"ClusterNodes": [
{
"NodeRole": "SHARED",
"PrivateIPAddress": "x.x.x.x,
"PublicIPAddress": "x.x.x.x"
}
],
"ClusterRevisionNumber": "62312",
"Tags": [],
"EnhancedVpcRouting": false,
"IamRoles": [],
"MaintenanceTrackName": "current",
"DeferredMaintenanceWindows": [],
"NextMaintenanceWindowStartTime": "2024-02-08T15:30:00+00:00",
"AvailabilityZoneRelocationStatus": "disabled",
"ClusterNamespaceArn": "arn:aws:redshift:ap-northeast-1:xxxxx:namespace:xxxxxxx",
"TotalStorageCapacityInMegaBytes": 400000,
"AquaConfiguration": {
"AquaStatus": "disabled",
"AquaConfigurationStatus": "auto"
},
"MultiAZ": "Disabled"
}
]
}
S3:バケットの作成
Redshiftで作成したデータおよびスキーマをBigQueryに転送する際は、ステージング領域としてAmazon S3のバケットが必要なため、S3バケットを作成しました。
BigQuery設定
BigQuery側で必要な作業は以下の2つです。
- データセットの作成
- データ転送設定
データセットの作成
まずはRedshiftで作成したデータを格納するためのデータセットをBigQueryで作成します。
以下は参考のパラメータです。その他パラメータはデフォルトで問題ありません。
| 項目 | 値 | 備考 |
|---|---|---|
| データセットID | RedShift_dataset | 任意の値 |
| ロケーションタイプ | リージョン(asia-northeast1) | 任意のリージョンで問題なし ※ 後続で記載するエラー対応のセキュリティグループ設定に影響あり |
データ転送設定
BigQueryの設定画面から「データ転送」>「転送を作成」を選択します。
ソースで「Migration: Redshift」を選んだ場合、設定に必要な項目が決まり、スケジュールオプションは「すぐに開始」が自動的に選択されます。
| 項目 | 値 | 備考 |
|---|---|---|
| ソース | Migration: Redshift | Redshiftを選択 |
| 転送構成名 | Transfer_Redshift | 任意の値 |
| スケジュールオプション | すぐに開始 | 変更不可 |
| データセット | RedShift_dataset | 「データセットの作成」で作成したデータセット名を指定 |
| JDBC connection url for Redshift | jdbc:redshift://xxxxxx.xxxxxx.ap-northeast-1.redshift.amazonaws.com:5439/dev | Redshiftコンソール画面で取得した値 |
| Username of your database | awsuser | Redshiftで作成したユーザ情報 |
| Password of your database | xxxxxx | Redshiftで作成したユーザ情報 |
| Access key ID | xxxxxx | IAMアクセスアクセスキー |
| Secret access key | xxxxxx | IAMシークレットアクセスアクセスキー |
| Amazon S3 URI | s3://xxxxxx | S3コンソール画面で取得した値 |
| Redshift schema | public | Redshiftで作成したスキーマ名 |
転送処理の実行
データ転送処理開始後に以下のエラーが出力されました。
Could not connect with provided parameters: The connection attempt failed.
改めて設定を確認したところ、Redshiftと疎通する際は、セキュリティグループのインバウンドルールにGoogle Cloudによって予約されているRedshiftデータ移行用のIPアドレスを許可する必要があることがわかりました。
上記を踏まえて、Redshiftが作成されているVPCに紐づくセキュリティグループのインバウンドルールを確認したところ、当該IPアドレスが許可されていなかったので、「データセットの作成」で指定したリージョン(asia-northeast1)に対応したIPアドレスをセキュリティグループのインバウンドルールに追加することでエラーが解消できました。
1つ目に出たエラー解決後に、以下の別エラーが出力されました。
Pod failed unexpectedly with exit code: 5
エラーの表記としては汎用エラーのため、すぐに原因を特定することは難しく、今までの設定を一通り見直すことになりました。今回の原因は「データ転送設定」で設定作成時に「Redshift schema」の値が誤っていたことが原因でした。
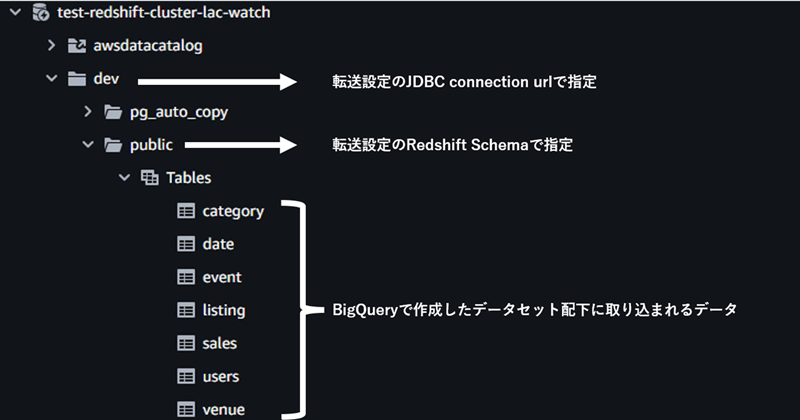
以下の画像がRedshiftで確認できるデータ構成ですが、エラー発生時は誤って「dev」を指定していました。スキーマ名としては「public」が適切だったため、修正後エラーは解消しました。Redshiftのコンソールから確認できるcluster配下の構成と、データ転送設定で指定するパラメータの対応は以下の通りです。
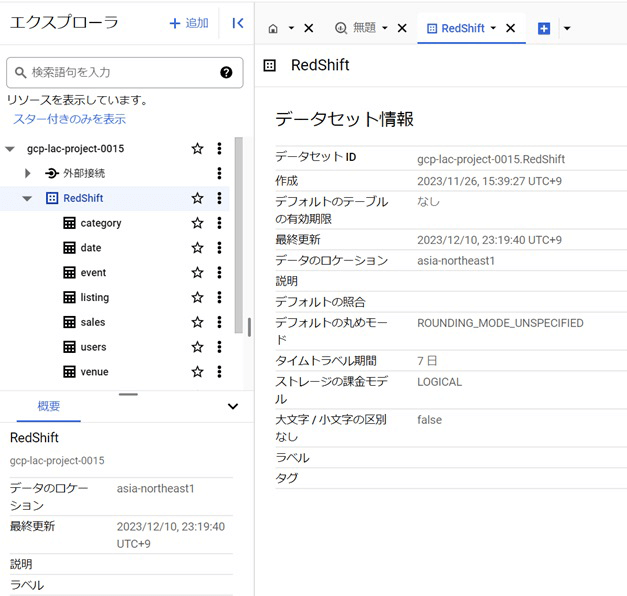
2つ目に出たエラーが解決すると、正常にデータ転送ができました。
Redshift上で扱っていたデータがBigQueryにも同じ形式で転送されました。
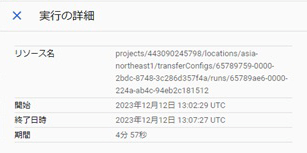
今回検証を行った環境では、Redshift上で0.36Gバイトのデータとして存在していました。データ転送には4分57秒の時間を要していました。Redshiftのノードタイプはdc2.largを選択していたこと、およびネットワークを介した通信の発生があったことで、少ないデータ量でも時間がかかるように感じました。
そのため小さいデータを毎回この方法で転送するには適していないようです。オンデマンド方式の課金体系に変わることも踏まえて、利用頻度の少ないデータの転送に適しているのではないかと思われます。
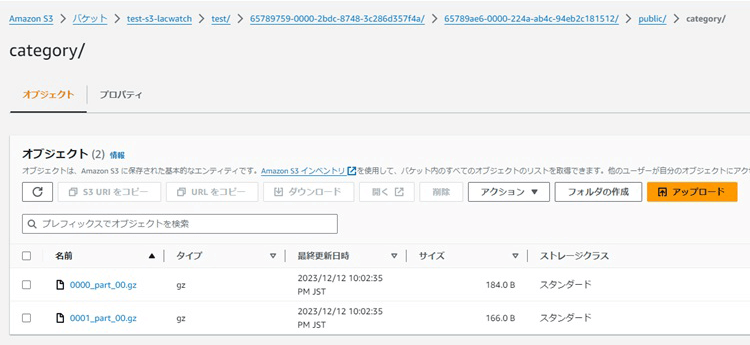
転送前はS3上にはtestフォルダ以外存在していませんでしたが、新しいフォルダが作成され、各テーブルのデータがgz形式の圧縮ファイルで保存されていました。このファイルは自動削除されなかったため、セキュリティ面も考慮して削除の対応もした方が良いと思います。
さいごに
本検証では、Redshift上のデータをBigQueryに移行して処理できるようにしました。
今回設定した内容は一度作成すれば、転送元のデータが更新された場合でもGoogle Cloud側からの操作ひとつで再度転送を行うことが可能です。そのため継続的な利用が簡単です。
また、性能比較でも述べましたが、RedshiftとBigQueryは料金体系が異なります。データ分析の一元化だけではなく、データの利用方法を考慮してコスト面でもメリットがある使い分けを期待できるので、ぜひ検討してみてください。
プロフィール

CCoE部AWS推進チーム
CCoE部AWS推進チームではAWSの各サービスを最大限活用するために日々技術検証や教育プログラムの検討を行っております。その活動のなかで得られた有益な情報を外部へ発信していきます。
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR