
-
タグ
タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR











イノベーション推進部イノベーション開発グループ(以下、InnoDev)の南です。
InnoDevは、ヒアリングに基づいたお客様の業務課題やニーズに対して、AI技術を活用した新規プロダクト開発することをミッションとしています。お客様への価値提供の手段として、AI/データ分析ソリューションの提案、AIソリューションの概念実証実験、AIソリューションのMVP開発を行っています。また、先端技術の獲得として社内AI研修の提供、大学などの学術機関との共同研究、技術検証業務も実施しています。
私はその中でも、AIに関する研修コンテンツの提供、および情報の発信をメインに取り組んできました。その中でも大きな結果のひとつである、社内向けAI開発研修の提供についてご紹介します。
AI開発研修を始めたきっかけ
昨年度から、金融犯罪に対する不正検知モデルの実証実験をはじめとした、AI関連の案件が徐々に増えてきています。そのため、AIの技術を理解して開発できるような体制を、全社的に構築する必要が生じてきました。これを実現するための研修を提供したいと考えたことが、コンテンツ作りのきっかけです。
折しも、経営層より「全SEに実務的なAI開発スキルを身に付ける研修を構築できますか?」という、私にとっては渡りに船な話があり、「はい、構築できます」と回答しました。技術職だけでなく営業職やマネジメント層、およびコーポレート部門の社員も含むすべての社員が、これまでに培ったスキルや経験を基に「データを活用するスキル」「AIを事業に活かすスキル」を身に付けなければならないという、ラック経営層の信念に基づいた、ひとつの施策になるのではないかと感じたのです。トップとボトムの考えが一致した流れに乗り、コンテンツ作りを開始しました。
AI開発研修の特徴
「AI開発研修」とは、文字通り「AIを開発するためのスキルを取得するための研修」です。AI開発に必要な知識を列挙しだすと、膨大で流動的なものになるのではと想像するかと思います。流行り廃りも早かったり、新しい概念やプロダクトが日々誕生していたりするのは、多くのエンジニアが感じていることでしょう。しかし、「本当に中核として身に付けてほしい部分」については、若干抽象的で小難しいテーマが多いものの、いつまでも陳腐化しない傾向にあります。そのような傾向もふまえて、3日間コースのコンテンツを作り上げました。コンテンツの具体的な内容ですが、特に以下のような特徴があります。
- 前処理や特徴量エンジニアリングの内容が約4割
- 基本的な評価指標について、ビジネスとどのように直結するかの例も含める
- 汎化性能、アンサンブル学習、クロスバリデーション、勾配降下法などの理論面に近い内容についても基本的な考え方を中心に真正面から取り扱う
- 学習器はロジスティック回帰と決定木に限定
- ハンズオンのテーマは必修・アドバンストの2つのレベルを用意

前処理や特徴量エンジニアリングは、AIの性能の8割ほどを左右すると言われるくらい非常に重要なプロセスです。しかしながら、研修資料を集めていたとき、入門用のコンテンツの内容が不足していました。一方で、中級者以上のコンテンツは詳細化されすぎており、バランス良く体系だったコンテンツがなかなかありませんでした。そのような事情から、前処理や特徴量エンジニアリングの重要性を前面に押し出しつつ、最低限の体系的な知識を取得できるように作りこみました。
AI開発は、あくまで「AIを用いてお客様のビジネスをよりよくすること」を目的として行うものです。世間では「AIは自動的になんでもすごい機能を提供してくれる」かのような誤解もしばしば見受けられますが、決してそんなことはありません。お客様のビジネスを知り、そのビジネスの課題に合わせたチューニングが必要になります。その際にはお客様との折衝が生じますが、AI特有の折衝方法についても丁寧に説明しています。
AI開発研修におけるハンズオンについて
AI開発研修は、基本的に社員に貸与されている標準PC(OSはWindows)に、データ分析に使う「JupyterLab」の環境を一時的に導入して行います。
当初、Python開発環境を管理する「miniconda」で構築をする方針をとっていました。しかし、この方針では手順書に基づいた手作業の工程が発生してしまうこともあり、なるべくバッチファイルなどの操作で完結できないかを模索するようになりました。それを実現するために、「Embeddable Python」を用いて、ポータブルな環境となるような形をとりました。しかし、こちらの方法も、社内で使用しているOneDriveとの相性の悪さが気になるところもあり、別の方針を模索している段階です。
ハンズオンで扱う主要なライブラリは、以下のものになります。
必修の対象となるライブラリ
- NumPy
- pandas
- Matplotlib
- seaborn
- scikit-learn
- LightGBM
アドバンストのみで扱うライブラリ
- Category Encoders
- xfeat
- XGBoost
- CatBoost
- Optuna
ライブラリについては、見る人が見れば標準的かつ汎用的のものがメインの構成になっていることに気づくかと思います。以下に例の一部をお見せいたします。そのライブラリ群を用いて「単に結果を出力できるようになる」だけではなく、「理論で学んだ状況を手元で実際に再現させ、理論で学んだことを肌で感じることを重視している」ことが少しでも伝われば幸いです。
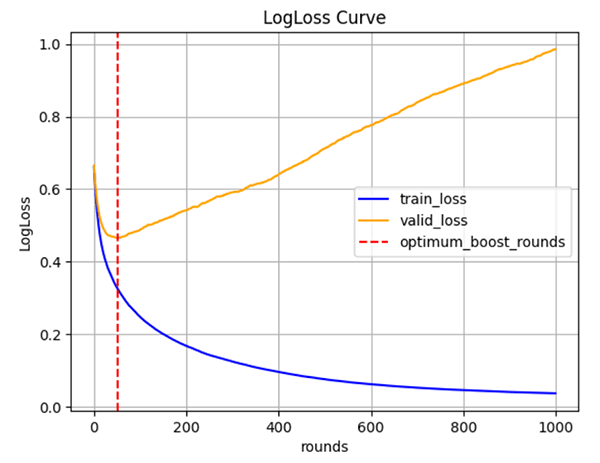
LightGBMにて、学習データと検証データの損失の推移と、最良のイテレーションを可視化したグラフです。一定のイテレーションを超えると、検証データの損失が大きくなることを確認し、必要以上に無駄なイテレーションを重ねないために早期終了という仕組みを利用することを理解してもらいます。
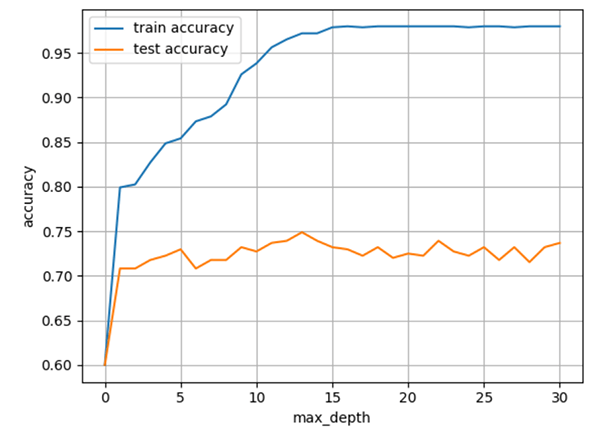
scikit-learnのランダムフォレストにおける、max_depthの値を大きくしたときの正解率の推移を可視化したグラフです。モデルは複雑にすれば精度がよくなるわけではなく、過学習を引き起こすことが理解できます。
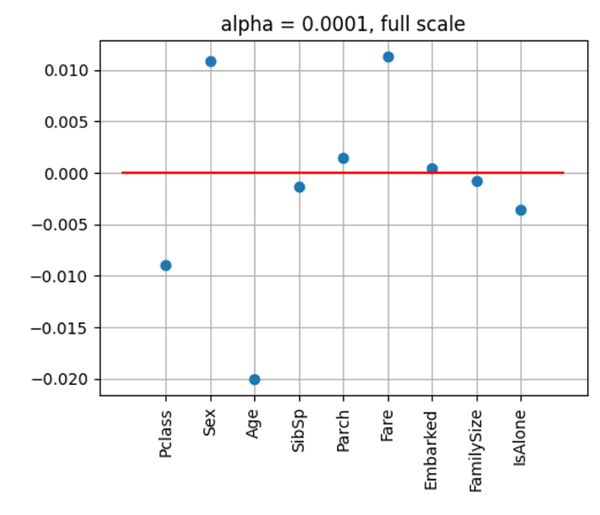
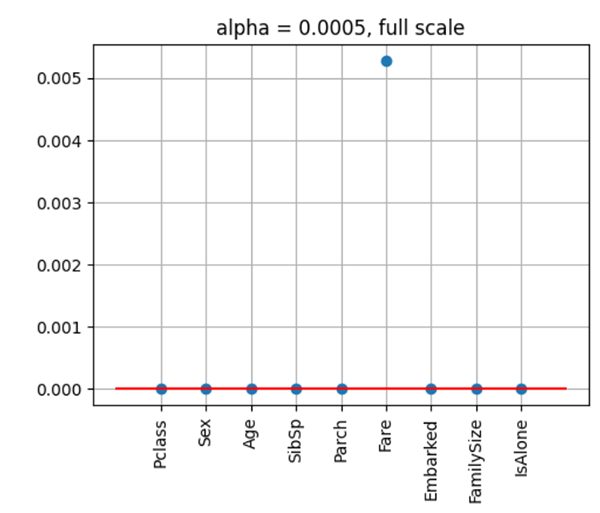
ロジスティック回帰のL1正則化(左図)とL2正則化(右図)のパラメータ変化のシミュレーションです。
ロジスティック回帰のL1正則化(上図)とL2正則化(下図)のパラメータ変化のシミュレーションです。
AI開発研修を開催してみて
コンテンツの制作は4月に開始し、6月末にバージョン1.0が完成しました。それをもとに、自分が所属する統括部の新人向けに研修し、その後ラックの新人を中心にのべ60人に研修を実施してきました。
| A統括部 新人研修 | 4人 | 6月27日~29日 |
| B統括部 新人研修 | 13人 | 7月27日~29日 |
| C統括部 新人研修 | 13人 | 8月3日~5日 |
| D統括部 新人研修 | 12人 | 10月3日~5日 |
| E統括部 新人研修 | 16人 | 10月17日~19日 |
| F社(ラックグループ会社)向け | 3人 | 11月16日~18日 |
新人研修がメインで、興味ある一部の若手社員が受講しているケースもあります。実際に研修を開催してみると、最近入社する年代はAI開発に関する素養が非常に高く、中堅層以上の年代と若手の間にはAIに対する様々な考え方や知識に隔たりがあることに気づきました。学校のカリキュラムにAI関連の科目が組み込まれていたり、研究の手法として定着していたりする側面もあり、日常的にAIに接するケースが増えているのが大きく影響していそうです。研修を通じて、このような状況を肌で感じることができたのは非常に大きかったと思います。一方で、若手の持つポテンシャルを生かし切るような環境づくりは、今後の新たな課題になっていきそうです。
さいごに
今後もAI人材の発掘や育成をふまえた、対面形式の研修を継続させていきたいと考えています。特に中堅層以上の技術者に対してもスキルの取得のみならず、AIの開発をきっかけとした新たなコミュニケーションの種になることを望んでいます。また、忙しい現場エンジニアでも何らかの形で学習できる仕組みを提供したいと思い、動画を交えたオンデマンド学習の提供も併せて取り組んでいます。
この研修が『たしかなテクノロジーで「信じられる社会」を築く。』というラックのパーパスに直結したコンテンツとして根づくよう、改善を重ねていきたいと思います!
この記事をシェアする
関連記事









タグ
- アーキテクト
- アジャイル開発
- アプリ開発
- インシデントレスポンス
- イベントレポート
- カスタマーストーリー
- カルチャー
- 官民学・業界連携
- 企業市民活動
- クラウド
- クラウドインテグレーション
- クラブ活動
- コーポレート
- 広報・マーケティング
- 攻撃者グループ
- もっと見る +
- 子育て、生活
- サイバー救急センター
- サイバー救急センターレポート
- サイバー攻撃
- サイバー犯罪
- サイバー・グリッド・ジャパン
- サプライチェーンリスク
- システム開発
- 趣味
- 障がい者採用
- 初心者向け
- 白浜シンポジウム
- 情シス向け
- 情報モラル
- 情報漏えい対策
- 人材開発・教育
- 診断30周年
- スレットインテリジェンス
- すごうで
- セキュリティ
- セキュリティ診断
- セキュリティ診断レポート
- 脆弱性
- 脆弱性管理
- ゼロトラスト
- 対談
- ダイバーシティ
- テレワーク
- データベース
- デジタルアイデンティティ
- 働き方改革
- 標的型攻撃
- プラス・セキュリティ人材
- モバイルアプリ
- ライター紹介
- ラックセキュリティアカデミー
- ランサムウェア
- リモートデスクトップ
- 1on1
- AI
- ASM
- CIS Controls
- CODE BLUE
- CTF
- CYBER GRID JOURNAL
- DevSecOps
- DX
- EC
- EDR
- FalconNest
- IoT
- IR
- JSOC
- JSOC INSIGHT
- LAC Security Insight
- NDR
- OWASP
- SASE
- Tech Crawling
- XDR