
-
タグ
タグ
- セキュリティ
- 人材開発・教育
- システム開発
- アプリ開発
- モバイルアプリ
- DX
- AI
- サイバー攻撃
- サイバー犯罪
- 標的型攻撃
- 脆弱性
- 働き方改革
- 企業市民活動
- 攻撃者グループ
- JSOC
- JSOC INSIGHT
- サイバー救急センター
- サイバー救急センターレポート
- LAC Security Insight
- セキュリティ診断レポート
- サイバー・グリッド・ジャパン
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- ラックセキュリティアカデミー
- すごうで
- ランサムウェア
- ゼロトラスト
- SASE
- デジタルアイデンティティ
- インシデントレスポンス
- 情シス向け
- 対談
- CIS Controls
- Tech Crawling
- クラウド
- クラウドインテグレーション
- データベース
- アジャイル開発
- DevSecOps
- OWASP
- CTF
- FalconNest
- セキュリティ診断
- サプライチェーンリスク
- スレットインテリジェンス
- テレワーク
- リモートデスクトップ
- アーキテクト
- プラス・セキュリティ人材
- 官民学・業界連携
- カスタマーストーリー
- 白浜シンポジウム
- CODE BLUE
- 情報モラル
- クラブ活動
- 初心者向け
- 趣味
- カルチャー
- 子育て、生活
- 広報・マーケティング
- コーポレート
- ライター紹介
- IR








システムを使う上で、障害を完全になくすことはできません。そして、いざ障害が発生し、システムが正常に動作しない状況に陥ると、多大な損害が発生することもあります。そのため、システム構築では障害に備えて冗長性を確保し、事前に障害検証を行い、障害が起きてもシステムが正常に動作することを確認します。
しかし、現在の主流である「分散システム」は、多数のサービスを組み合わせることで1つのシステムを実現させるため、規模が大きくなるにつれてシステムが複雑化していきます。それに伴い、障害検証の負荷も増えています。さらに、昨今コンテナを利用した「マイクロサービス化」によって、ますますサービスの数が増えて、システムの複雑化が一段と進んでいる状況です。既に人力だけでは障害検証を行っていくことが難しくなってきました。
そんな中、登場してきたのが今回お話する「カオスエンジニアリング」です。
Chaos Meshとは
カオスエンジニアリングは、障害を意図的に発生させて、障害時でもシステムが正常に動作することや復旧ができることを確認したり、障害時に起こる異常な動作から原因を究明してシステムを改善することを繰り返すことで、システムの耐障害性を高めたりする取り組みです。その際に、意図的な障害を手動で起こしていたのでは作業負荷が大きくなり、長期的な持続が不可能であるため、自動化して無理なく継続することを目指しています。そのため、自動化のためのツールが必要になります。
今回検証する「Chaos Mesh※」は、マイクロサービスをコンテナ化し、コンテナ化したアプリケーションを管理するオーケストレーションツール「Kubernetes」でカオスエンジニアリングを実施できるツールです。ここでは、Kubernetes環境として、AWSでマネージドKubernetesを実行する「AWS EKS」を利用します。
※ A Powerful Chaos Engineering Platform for Kubernetes | Chaos Mesh
Chaos Meshの導入
それでは早速、KubernetesにChaos Meshを導入してみましょう。Chaos Meshの導入方法は、インストールスクリプトで導入する方法と、Kubernetesのパッケージマネージャ「helm」で導入する方法の2パターンあります。テスト環境はインストールスクリプト、本番環境ではhelmの導入を推奨しています。今回は検証目的であるため、インストールスクリプトでの導入を行います。
Chaos Meshの導入
以下のコマンドを実行し、Chaos Meshを導入します。
# curl -sSL https://mirrors.chaos-mesh.org/v2.1.2/install.sh | bash Install Chaos Mesh chaos-mesh customresourcedefinition.apiextensions.k8s.io/awschaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/dnschaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/gcpchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/httpchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/iochaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/jvmchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/kernelchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/networkchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/physicalmachinechaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/podchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/podhttpchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/podiochaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/podnetworkchaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/schedules.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/stresschaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/timechaos.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/workflownodes.chaos-mesh.org created customresourcedefinition.apiextensions.k8s.io/workflows.chaos-mesh.org created namespace/chaos-testing created serviceaccount/chaos-daemon created serviceaccount/chaos-controller-manager created secret/chaos-mesh-webhook-certs created clusterrole.rbac.authorization.k8s.io/chaos-mesh-chaos-controller-manager-target-namespace created clusterrole.rbac.authorization.k8s.io/chaos-mesh-chaos-controller-manager-cluster-level created clusterrolebinding.rbac.authorization.k8s.io/chaos-mesh-chaos-controller-manager-cluster-level created clusterrolebinding.rbac.authorization.k8s.io/chaos-mesh-chaos-controller-manager-target-namespace created role.rbac.authorization.k8s.io/chaos-mesh-chaos-controller-manager-control-plane created rolebinding.rbac.authorization.k8s.io/chaos-mesh-chaos-controller-manager-control-plane created service/chaos-daemon created service/chaos-dashboard created service/chaos-mesh-controller-manager created daemonset.apps/chaos-daemon created deployment.apps/chaos-dashboard created deployment.apps/chaos-controller-manager created mutatingwebhookconfiguration.admissionregistration.k8s.io/chaos-mesh-mutation created validatingwebhookconfiguration.admissionregistration.k8s.io/chaos-mesh-validation created validatingwebhookconfiguration.admissionregistration.k8s.io/validate-auth created Waiting for pod running Waiting for pod running Chaos Mesh chaos-mesh is installed successfully # echo $? 0
Chaos Mesh導入後の確認
Chaos Meshの導入後、導入が正しく完了していることを確認します。
# kubectl get po -n chaos-testing NAME READY STATUS RESTARTS AGE chaos-controller-manager-588df5cdd7-h9kht 1/1 Running 0 2m1s chaos-controller-manager-588df5cdd7-mj2rl 1/1 Running 0 2m1s chaos-controller-manager-588df5cdd7-zr8bp 1/1 Running 0 2m1s chaos-daemon-4nndz 1/1 Running 0 2m1s chaos-daemon-5tpql 1/1 Running 0 2m1s chaos-dashboard-7c87549798-xwd4f 1/1 Running 0 2m1s
chaos-testing namespaceのpodが全てRunningになったら導入完了です。
chaos-dashboardの公開設定
Chaos MeshのWebUIであるChaos Dashboardにブラウザでアクセスするために、chaos-dashboardのserviceをLoadBalancerに変更します。
# kubectl patch svc chaos-dashboard -n chaos-testing -p '{"spec": {"type": "LoadBalancer"}}'
# kubectl get svc chaos-dashboard -n chaos-testing
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
chaos-dashboard LoadBalancer 10.100.162.19 xxxxxxxxxxxxxxxxxxxxxxxxxx-yyyyyyyyy.ap-northeast-1.elb.amazonaws.com 2333:32032/TCP 8d
chaos-dashboardのTYPEがLoadBalancerになり「EXTERNAL-IP」が付与されていることを確認します。これでブラウザからアクセス可能になりました。
ブラウザからchaos-dashboardへの接続
ブラウザのアドレスバーに「EXTERNAL-IP:2333」を入力してChaos Dashboardに接続します。
接続に成功すると以下のような画面が表示されます。こちらがChaos Meshのダッシュボード画面になっており、左のメニューバーから項目を選択し、右のメイン画面では状態の確認や操作ができます。
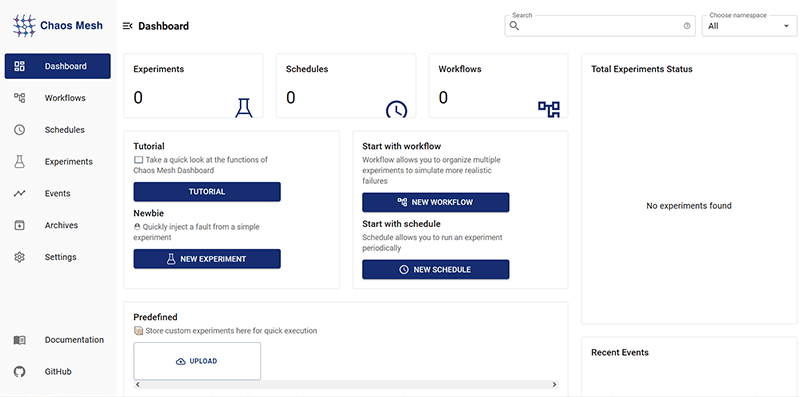
Chaos Meshで実験可能な障害
2022年2月現在、Chaos Meshで実験できる項目は以下の通りです。今回はこちらからPodChaosとStressChaosを取り上げ、実験してみます。
| PodChaos | PodChaos | ポッドの再起動、ポッドの永続的な使用不可、特定のポッドでの特定のコンテナの障害などのポッドの障害をシミュレートします。 |
|---|---|---|
| NetworkChaos | ネットワーク遅延、パケット損失、パケット障害、ネットワークパーティションなどのネットワーク障害をシミュレートします。 | |
| DNSChaos | DNSドメイン名の解析の失敗や、間違ったIPアドレスが返されるなどのDNSの失敗をシミュレートします。 | |
| HTTPChaos | HTTP通信の遅延などのHTTP通信の失敗をシミュレートします。 | |
| StressChaos | CPU負荷またはメモリ負荷をシミュレートします。 | |
| IOChaos | I/Oの遅延や読み取りおよび書き込みの失敗などのI/Oの失敗をシミュレートします。 | |
| TimeChaos | タイムオフセットなどの時間障害をシミュレートします。 | |
| KernelChaos | メモリ割り当ての例外などのカーネルの障害をシミュレートします。 | |
| AWSChaos | AWSノードの再起動などのAWSプラットフォームの障害をシミュレートします。 | |
| GCPChaos | GCPノードの再起動などのGCPプラットフォームの障害をシミュレートします。 | |
| JVMChaos | 関数呼び出しの遅延などのJVMアプリケーションの障害をシミュレートします。 |
PodChaos
それでは、早速PodChaosを実験してみましょう。
PodChaos実験前の確認
実験前のPodの状態を確認します。
# kubectl get pod -n yogawa-ns01 -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7848d4b86f-lsvmt 1/1 Running 0 6d 192.168.81.59 ip-192-168-95-73.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-qvfrq 1/1 Running 0 6d 192.168.63.103 ip-192-168-33-82.ap-northeast-1.compute.internal <none> <none>
筆者の個人用namespace「yogawa-ns01」でnginxのPodが稼働しています。こちらのPodはReplicaSetで作成しており、Podが停止してもReplicaSetによりPodが再作成されて復旧します。想定通りの挙動をするか、PodChaosで実験してみたいと思います。
Experimentsの設定
Chaos Dashboardで以下の設定を行います。
- 左メニューの「Experiments」を選択
- 「NEW EXPERIMENTS」を選択
- 以下を設定
- - Experiment Type:KUBERNETES -> POD FAULT -> POD KILL
- - SCOPE:任意のnamespace(yogawa-ns01)
- - Metadata:任意の名前(pod-kill01)
- その他を必要に応じて設定し、「SUBMIT」を押下
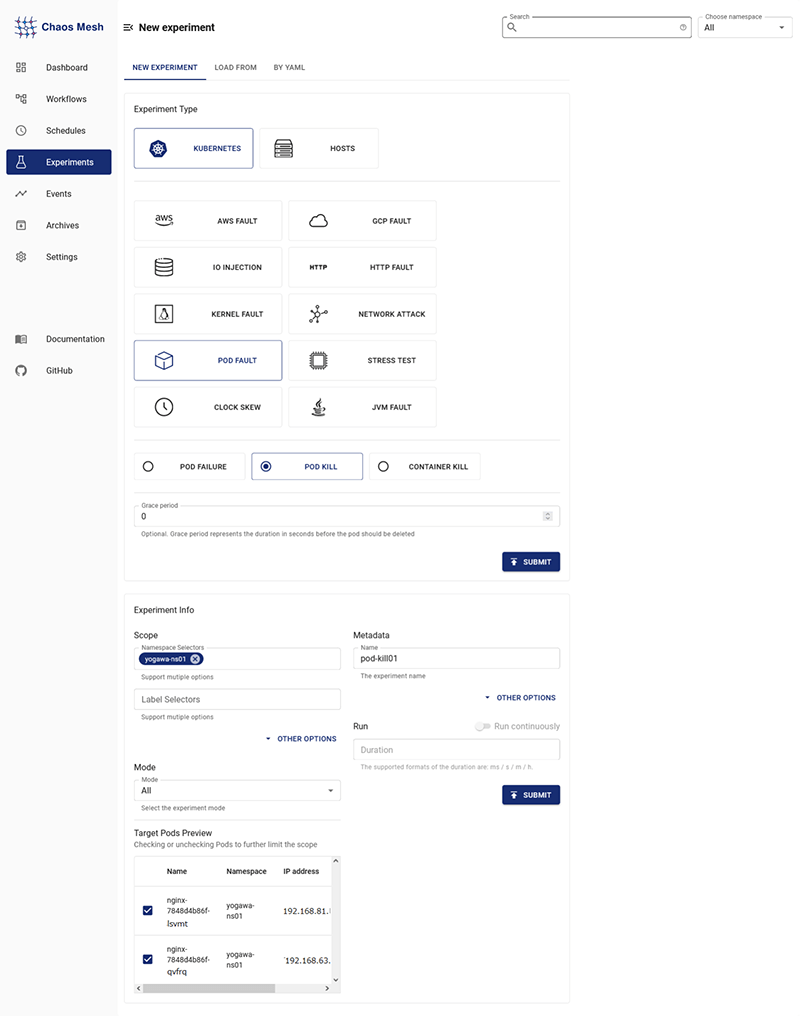
以下画面の通り、「Finished」が表示されたら成功です。
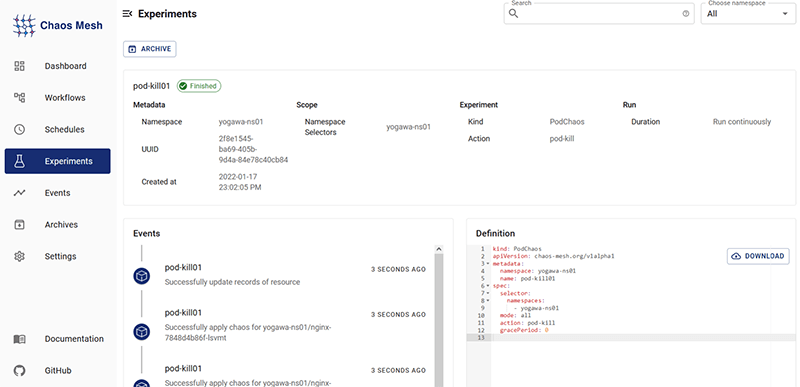
結果画面のDefinitionに表示されている通り、設定はyamlでも可能です。
今回のyamlは以下になります。コードで管理することで再利用や差分管理も容易になるので、要件に合わせてGUIやyamlを使い分けていくのが良いでしょう。
kind: PodChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
namespace: yogawa-ns01
name: pod-kill01
spec:
selector:
namespaces:
- yogawa-ns01
mode: all
action: pod-kill
gracePeriod: 0
PodChaos実験後の確認
PodChaos後のPodの状態を見てみたいと思います。
# kubectl get pod -n yogawa-ns01 -o wide -w NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-7848d4b86f-qvfrq 1/1 Terminating 0 6d 192.168.63.103 ip-192-168-33-82.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-qvfrq 1/1 Terminating 0 6d 192.168.63.103 ip-192-168-33-82.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-lsvmt 1/1 Terminating 0 6d 192.168.81.59 ip-192-168-95-73.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-lsvmt 1/1 Terminating 0 6d 192.168.81.59 ip-192-168-95-73.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-nlkrx 0/1 Pending 0 0s <none> <none> <none> <none> nginx-7848d4b86f-nlkrx 0/1 Pending 0 0s <none> ip-192-168-33-82.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-nlkrx 0/1 ContainerCreating 0 0s <none> ip-192-168-33-82.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-mzl2g 0/1 Pending 0 0s <none> <none> <none> <none> nginx-7848d4b86f-mzl2g 0/1 Pending 0 0s <none> ip-192-168-95-73.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-mzl2g 0/1 ContainerCreating 0 0s <none> ip-192-168-95-73.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-mzl2g 1/1 Running 0 3s 192.168.65.172 ip-192-168-95-73.ap-northeast-1.compute.internal <none> <none> nginx-7848d4b86f-nlkrx 1/1 Running 0 4s 192.168.32.108 ip-192-168-33-82.ap-northeast-1.compute.internal <none> <none>
想定通り障害前のPod(nginx-7848d4b86f-lsvmt、nginx-7848d4b86f-qvfrq)が停止し、自動的にPod(nginx-7848d4b86f-mzl2g、nginx-7848d4b86f-nlkrx)が再作成されて復旧したことが確認できました。
イベントも確認してみます。
# kubectl get events -n yogawa-ns01 -w LAST SEEN TYPE REASON OBJECT MESSAGE 0s Normal FinalizerInited podchaos/pod-kill01 Finalizer has been inited 0s Normal Updated podchaos/pod-kill01 Successfully update finalizer of resource 0s Normal Updated podchaos/pod-kill01 Successfully update desiredPhase of resource 0s Normal Applied podchaos/pod-kill01 Successfully apply chaos for yogawa-ns01/nginx-7848d4b86f-qvfrq 0s Warning FailedToUpdateEndpoint endpoints/nginx Failed to update endpoint yogawa-ns01/nginx: Operation cannot be fulfilled on endpoints "nginx": the object has been modified; please apply your changes to the latest version and try again 0s Normal Killing pod/nginx-7848d4b86f-lsvmt Stopping container nginx 0s Normal Killing pod/nginx-7848d4b86f-lsvmt Stopping container nginx 0s Normal SuccessfulCreate replicaset/nginx-7848d4b86f Created pod: nginx-7848d4b86f-nlkrx 0s Normal Applied podchaos/pod-kill01 Successfully apply chaos for yogawa-ns01/nginx-7848d4b86f-lsvmt 0s Normal Killing pod/nginx-7848d4b86f-qvfrq Stopping container nginx 0s Normal Scheduled pod/nginx-7848d4b86f-nlkrx Successfully assigned yogawa-ns01/nginx-7848d4b86f-nlkrx to ip-192-168-33-82.ap-northeast-1.compute.internal 0s Normal Updated podchaos/pod-kill01 Successfully update records of resource 0s Normal Killing pod/nginx-7848d4b86f-qvfrq Stopping container nginx 0s Normal Scheduled pod/nginx-7848d4b86f-mzl2g Successfully assigned yogawa-ns01/nginx-7848d4b86f-mzl2g to ip-192-168-95-73.ap-northeast-1.compute.internal
イベントに「podchaos/pod-kill01」が実行されていることが記録されていました。発生した障害がChaos Meshによる実験なのか本当の障害なのかをきちんと区別することが可能です。
EKSへのメトリクスサーバ導入
こちらの手順は後続手順の前提になります。
KubernetesのCPUやメモリ使用率はkubectl top nodeで見ることが可能ですが、EKSはデフォルトではメトリクスサーバが導入されていないので、まずはメトリクスサーバを導入します。詳細は以下のドキュメントをご参照ください。
Installing the Kubernetes Metrics Server - Amazon EKS
メトリクスサーバ導入前の確認
# kubectl top node W0118 12:44:18.183062 32017 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag error: Metrics API not available
メトリクスサーバが導入されていないので「error: Metrics API not available」といったエラーが表示されます。この時点で正常にCPUやメモリの状態が確認できる場合は、後続手順は不要ですので、StressChaos実験に進んでください。
メトリクスサーバの導入
以下のコマンドを実行し、EKSへメトリクスサーバを導入します。
# kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml serviceaccount/metrics-server created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrole.rbac.authorization.k8s.io/system:metrics-server created rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created service/metrics-server created deployment.apps/metrics-server created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created # kubectl get deployment metrics-server -n kube-system NAME READY UP-TO-DATE AVAILABLE AGE metrics-server 1/1 1 1 32s
メトリクスサーバ導入後の確認
# kubectl top node --use-protocol-buffers NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-192-168-33-82.ap-northeast-1.compute.internal 145m 7% 1624Mi 23% ip-192-168-95-73.ap-northeast-1.compute.internal 119m 6% 1528Mi 21%
メトリクスサーバが導入され、無事にCPUとメモリ使用率を表示することができました。
StressChaos
次はCPUやメモリに負荷を掛ける、StressChaosを実験します。
StressChaos実験前の確認
実験前のPodの状態を確認してみます。
# date ; kubectl top node --use-protocol-buffers ; kubectl top pod -n yogawa-ns01 --use-protocol-buffers Tue Jan 18 13:15:32 UTC 2022 NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-192-168-33-82.ap-northeast-1.compute.internal 142m 7% 1628Mi 23% ip-192-168-95-73.ap-northeast-1.compute.internal 124m 6% 1517Mi 21% NAME CPU(cores) MEMORY(bytes) nginx-7848d4b86f-mzl2g 1m 3Mi nginx-7848d4b86f-nlkrx 1m 3Mi
CPU、メモリ共に、nginx Podではほとんど使用されていません。
それでは、StressChaosでCPUとメモリに負荷を掛けてみたいと思います。
Experimentsの設定
- 左メニューの「Experiments」を選択
- 「NEW EXPERIMENTS」を選択
- 以下を設定
- - Experiment Type:KUBERNETES -> STRESS TEST
- - CPU :worker -> 1 , load -> 50
- - Memory:worker -> 1 , size -> 2G
- - SCOPE:任意のnamespace(yogawa-ns01)
- - Metadata:任意の名前(stress-test01)
- その他を必要に応じて設定し、「SUBMIT」を押下
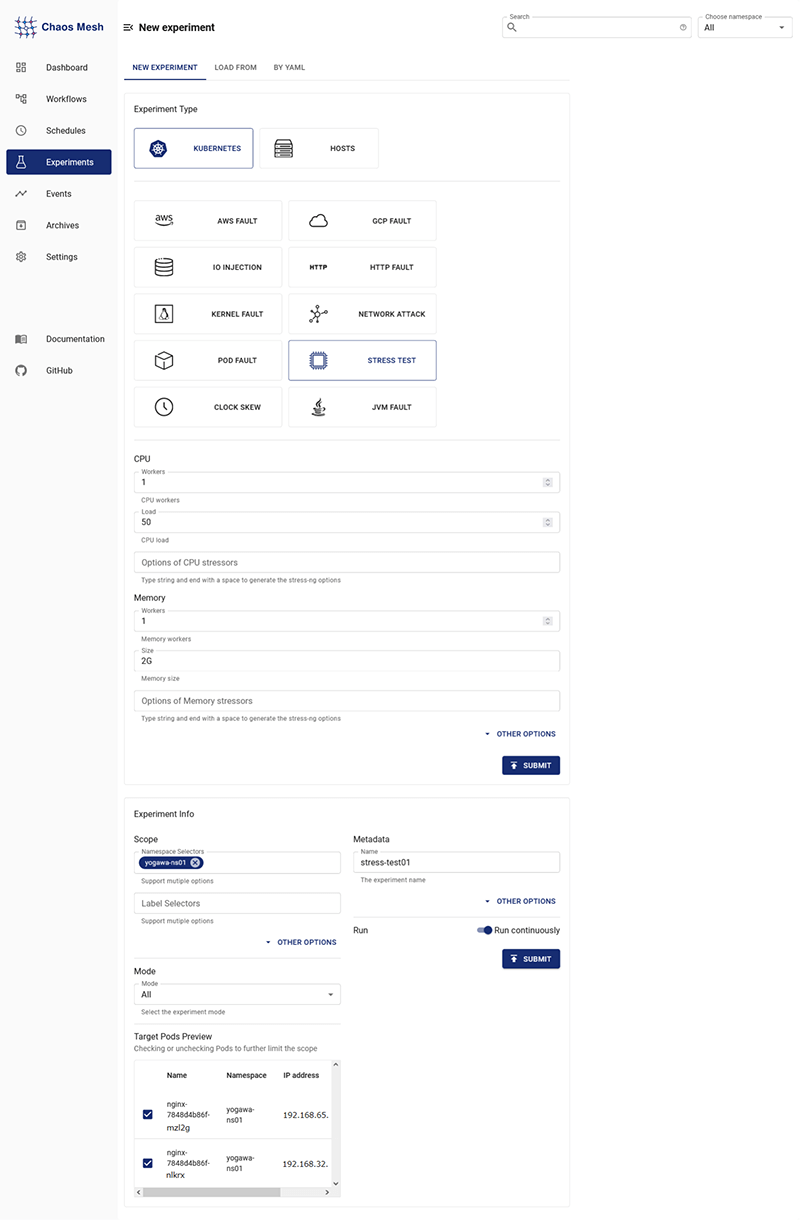
「Running」になれば、メモリとCPUに負荷を掛けている状態です。

StressChaos実験後の確認
StressChaos実験でCPUやメモリの状態がどうなっているかを確認します。
# date ; kubectl top node --use-protocol-buffers ; kubectl top pod -n yogawa-ns01 --use-protocol-buffers Tue Jan 18 13:20:36 UTC 2022 NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-192-168-33-82.ap-northeast-1.compute.internal 1520m 78% 3826Mi 54% ip-192-168-95-73.ap-northeast-1.compute.internal 1598m 82% 3627Mi 51% NAME CPU(cores) MEMORY(bytes) nginx-7848d4b86f-mzl2g 1422m 1920Mi nginx-7848d4b86f-nlkrx 1428m 1920Mi
CPUとメモリ共に負荷が掛かっていることが分かります。なお、メモリに負荷を掛けるとノードのCPU使用率が上がってしまうので、正確にCPU負荷だけの影響を見たい場合はメモリの負荷とは別々に実施するのが良いでしょう。
STRESS TESTの停止
Pauseを押すことで、STRESS TESTを停止することができます。STRESS TEST停止後に再度CPUとメモリの状態を確認します。
# date ; kubectl top node --use-protocol-buffers ; kubectl top pod -n yogawa-ns01 --use-protocol-buffers Tue Jan 18 13:26:27 UTC 2022 NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-192-168-33-82.ap-northeast-1.compute.internal 140m 7% 1802Mi 25% ip-192-168-95-73.ap-northeast-1.compute.internal 137m 7% 1703Mi 24% NAME CPU(cores) MEMORY(bytes) nginx-7848d4b86f-mzl2g 1m 3Mi nginx-7848d4b86f-nlkrx 1m 3Mi
STRESS TESTを停止したことで、事前の状態と変わらない負荷に戻りました。
参考までにイベントも貼っておきます。
54m Normal FinalizerInited stresschaos/stress-cpu01 Finalizer has been inited 54m Normal Updated stresschaos/stress-cpu01 Successfully update finalizer of resource 54m Normal Started stresschaos/stress-cpu01 Experiment has started 54m Normal Updated stresschaos/stress-cpu01 Successfully update desiredPhase of resource 54m Normal Applied stresschaos/stress-cpu01 Successfully apply chaos for yogawa-ns01/nginx-7848d4b86f-nlkrx/nginx 54m Normal Applied stresschaos/stress-cpu01 Successfully apply chaos for yogawa-ns01/nginx-7848d4b86f-mzl2g/nginx 54m Normal Updated stresschaos/stress-cpu01 Successfully update records of resource 53m Normal Paused stresschaos/stress-cpu01 Experiment has been paused 53m Normal Updated stresschaos/stress-cpu01 Successfully update desiredPhase of resource 53m Normal Recovered stresschaos/stress-cpu01 Successfully recover chaos for yogawa-ns01/nginx-7848d4b86f-nlkrx/nginx 53m Normal Recovered stresschaos/stress-cpu01 Successfully recover chaos for yogawa-ns01/nginx-7848d4b86f-mzl2g/nginx 53m Normal Updated stresschaos/stress-cpu01 Successfully update records of resource 49m Normal FinalizerInited stresschaos/stress-cpu01 Finalizer has been removed 49m Normal Updated stresschaos/stress-cpu01 Successfully update finalizer of resource 46m Normal FinalizerInited stresschaos/stress-test01 Finalizer has been inited 46m Normal Updated stresschaos/stress-test01 Successfully update finalizer of resource 46m Normal Started stresschaos/stress-test01 Experiment has started 46m Normal Updated stresschaos/stress-test01 Successfully update desiredPhase of resource 46m Normal Applied stresschaos/stress-test01 Successfully apply chaos for yogawa-ns01/nginx-7848d4b86f-nlkrx/nginx 46m Normal Applied stresschaos/stress-test01 Successfully apply chaos for yogawa-ns01/nginx-7848d4b86f-mzl2g/nginx 46m Normal Updated stresschaos/stress-test01 Successfully update records of resource 43m Normal Paused stresschaos/stress-test01 Experiment has been paused 43m Normal Updated stresschaos/stress-test01 Successfully update desiredPhase of resource 43m Normal Recovered stresschaos/stress-test01 Successfully recover chaos for yogawa-ns01/nginx-7848d4b86f-nlkrx/nginx 43m Normal Recovered stresschaos/stress-test01 Successfully recover chaos for yogawa-ns01/nginx-7848d4b86f-mzl2g/nginx 43m Normal Updated stresschaos/stress-test01 Successfully update records of resource 38m Normal FinalizerInited stresschaos/stress-test01 Finalizer has been removed 38m Normal Updated stresschaos/stress-test01 Successfully update finalizer of resource
最後に
以上、Chaos Meshを利用したカオスエンジニアリングを行いました。簡単な操作だけでPodChaosやStressChaosを実施することができ、想定通りの障害を起こすことができました。カオスエンジニアリングという言葉に対して難しいというイメージを持たれた方も、今回の記事を通して少し身近に感じられたのではないかと思います。Chaos Meshは今回検証した機能以外にも、様々な障害をシミュレーションすることが可能です。
ラックではKubernetesを利用した様々な構築・検証を行っております。Kubernetes環境でのカオスエンジニアリングにご興味がございましたら、ぜひラックにお問い合わせください。
この記事をシェアする
関連記事









タグ
- セキュリティ
- 人材開発・教育
- システム開発
- アプリ開発
- モバイルアプリ
- DX
- AI
- サイバー攻撃
- サイバー犯罪
- 標的型攻撃
- 脆弱性
- 働き方改革
- 企業市民活動
- 攻撃者グループ
- JSOC
- もっと見る +
- JSOC INSIGHT
- サイバー救急センター
- サイバー救急センターレポート
- LAC Security Insight
- セキュリティ診断レポート
- サイバー・グリッド・ジャパン
- CYBER GRID JOURNAL
- CYBER GRID VIEW
- ラックセキュリティアカデミー
- すごうで
- ランサムウェア
- ゼロトラスト
- SASE
- デジタルアイデンティティ
- インシデントレスポンス
- 情シス向け
- 対談
- CIS Controls
- Tech Crawling
- クラウド
- クラウドインテグレーション
- データベース
- アジャイル開発
- DevSecOps
- OWASP
- CTF
- FalconNest
- セキュリティ診断
- サプライチェーンリスク
- スレットインテリジェンス
- テレワーク
- リモートデスクトップ
- アーキテクト
- プラス・セキュリティ人材
- 官民学・業界連携
- カスタマーストーリー
- 白浜シンポジウム
- CODE BLUE
- 情報モラル
- クラブ活動
- 初心者向け
- 趣味
- カルチャー
- 子育て、生活
- 広報・マーケティング
- コーポレート
- ライター紹介
- IR